MonoFormer
MonoFormer: One Transformer for Both Diffusion and Autoregression阅读笔记
motivation
旨在构建并训练一个同时支持自回归和扩散方法的Transformer模型,其输入是经过embedding层投影的文本嵌入和带有噪声的图像潜变量,输出是预测的下一个token的文本嵌入和用于预测图像噪声的嵌入。
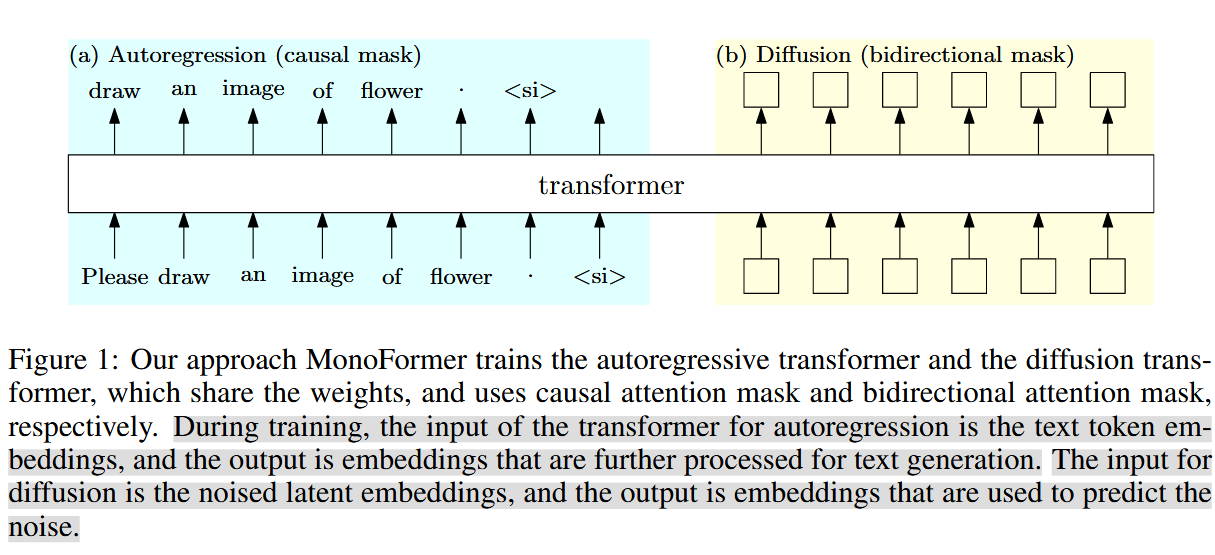
具体实现
对于文本使用自回归的模式生成,检测到生成特殊token ‘
去噪过程在潜空间进行,使用VAE encoder将图像patch映射到潜孔间,将带噪的潜变量与sine-cosine的位置嵌入相加。
与DiT相似,采用一个 256 维的频率嵌入对输入的时间步进行编码,随后通过两层带 SiLU 激活函数的MLP。使用AdaLN将时间嵌入和带噪潜变量融合。
与DiT不同的是,在处理本文(
带掩码的注意力机制可表示为:
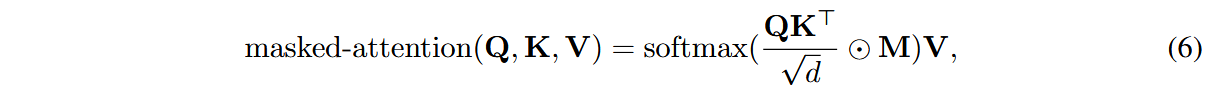
记
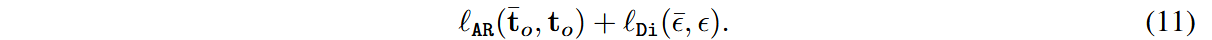
其中:
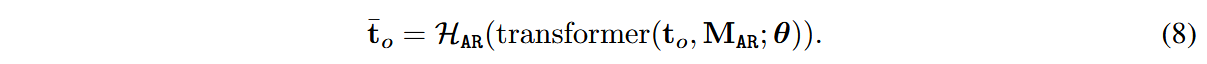
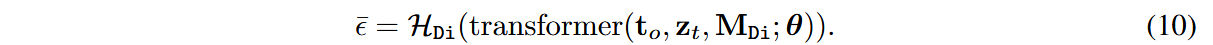
本博客所有文章除特别声明外,均采用 CC BY-NC-SA 4.0 许可协议。转载请注明来源 由本自性清净故,令诸爱染悉无垢!
