JanusFlow: Harmonizing Autoregression and Rectified Flow for Unified Multimodal Understanding and Generation阅读笔记
motivation
试图集成自回归模型和Rectified Flow模型,从而使用一个模型完成多模态理解与生成。
由于Rectified Flow 可以在LLM框架内直接训练,无需进行复杂的架构修改。
解耦理解与生成的编码器
现有方法多对理解与生成的输入使用同一个编码器,本文采用了解耦的编码器设计。具体而言,本文使用预训练的 SigLIP-Large-Patch/16 模型作为多模态理解编码器,从中提取用于多模态理解的语义连续特征;而对于生成任务,使用初始化的ConvNeXt模块作为生成的编码器和解码器,并在其之间加入了一条长跳跃连接。
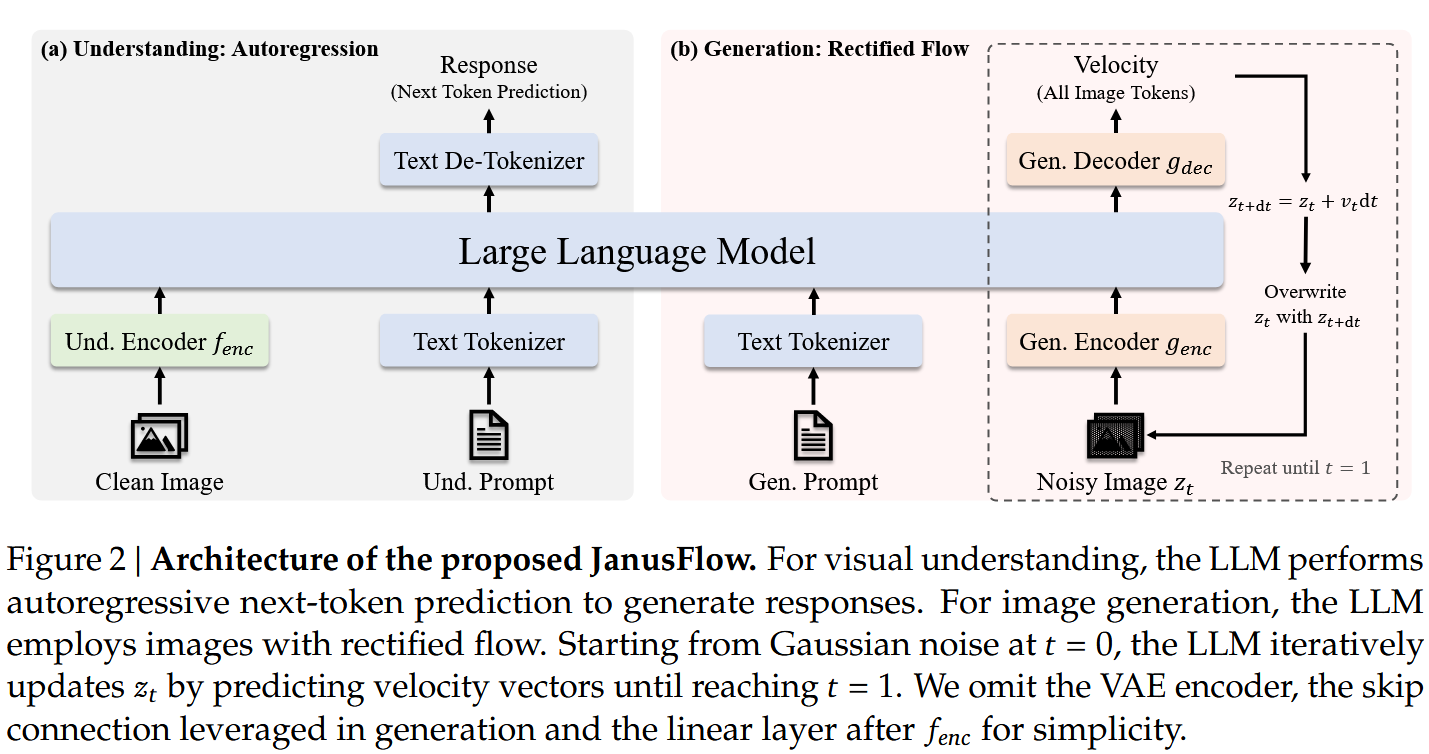
多模态理解
使用tokenizer解析输入文本,并转换为维的向量。图像使用编码为维度为的feature map,并使用线性层转换为维度为的向量序列。将文本与图像向量拼接后送入LLM中,在图像前后分别加入|BOI|和|EOI|的特殊字符。
图像生成
记输入的文本控制条件为,在SDXL-VAE的潜空间中进行Rectified Flow去噪。首先生成维度为,经过编码器转换为嵌入序列,与t时刻的时间嵌入拼接,使得序列长度变为,与大多数工作不同,无论是对图像输入还是文本输入,在注意力机制重均使用了因果掩码。LLM的输出最终经由解码器转换回并使用standard Euler solver进行更新,使用更新后的潜变量替换原始潜变量,不断迭代直至得到干净的潜变量再使用解码器转换为图像:
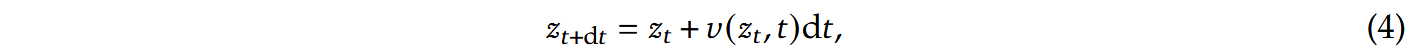
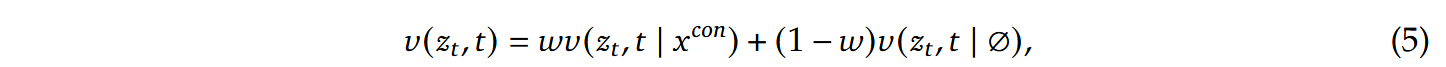
其中越大代表越侧重语义对齐。
训练流程
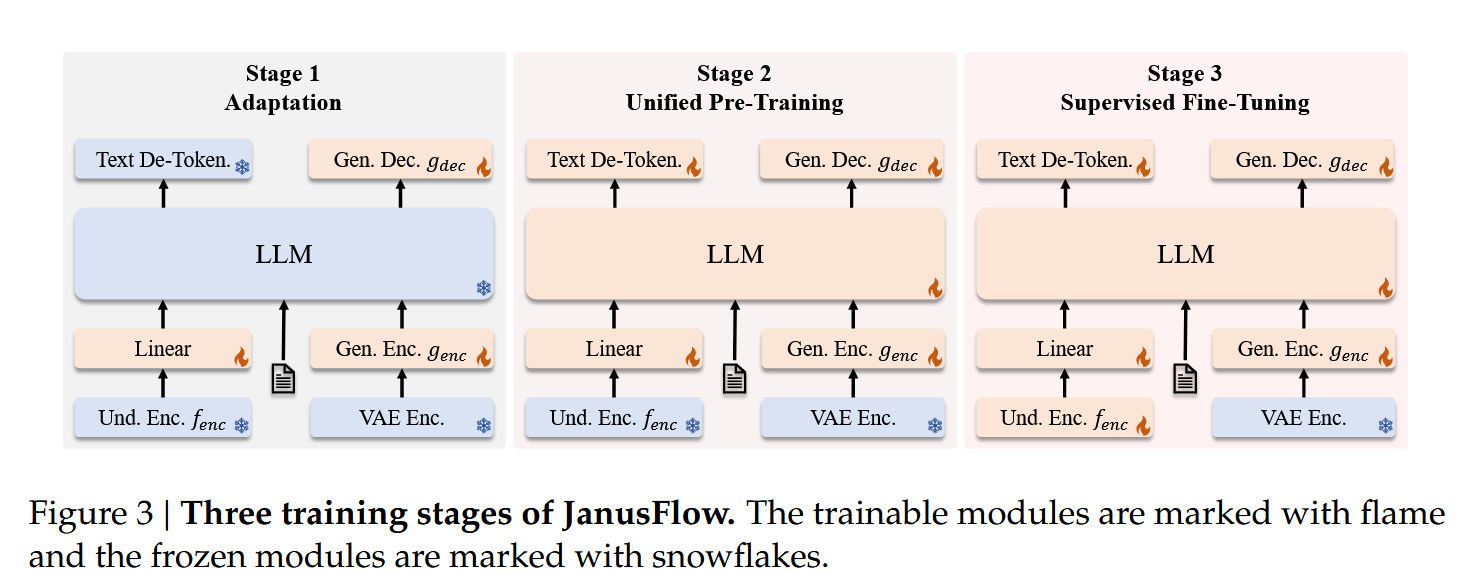
在第一阶段时仅对随机初始化的线性层、生成编码器和生成解码器 进行训练。
第二阶段使用多模态理解数据、图像生成数据和纯文本数据对除了visual encoder外的所有组件进行训练,前期训练数据中多模态理解数据占比更多,后期图像生成数据占比更多。
第三阶段对除了外的所有组件进行指令微调
记输入的条件数据为,目标结果为,,分别为的序列长度。
对于多模态理解任务,只包含文本数据,训练目标可表示为:
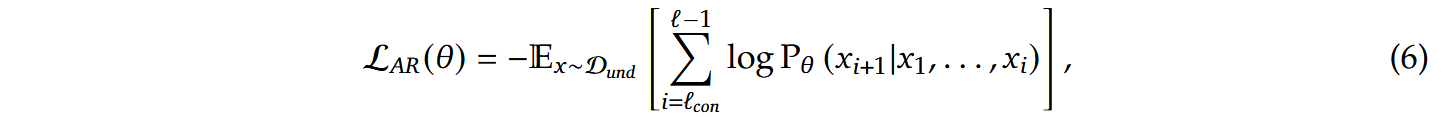
对于图像生成任务,记, P(t)服从 logit-normal 分布,为了达到CFG的效果,以10%的概率丢弃文本指令。训练目标可表示为:
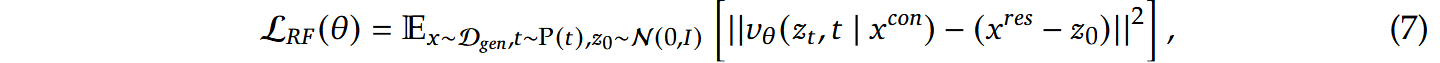
为了将DiT与语义视觉编码器之间的中间表示进行对齐,记表示给定输入后得到LLM中间表示,而是一个小型的可训练MLP,用于将映射到维度为的空间。函数用于计算嵌入向量逐元素余弦相似度的均值。在计算损失之前,将 重塑为形状为 的张量。此外,该损失的梯度不计入的反向传播过程中:

最终图像生成任务的损失函数可记作。
