Transfusion
Transfusion: Predict the Next Token and Diffuse Images with One Multi-Modal Model阅读笔记
motivation
旨在提出一种同时处理和生成文本和图像信息的方法,探讨如何组合离散序列建模(next token prediction)和diffusion这两种技术,本方法对于不同模态的输入采取不一样的生成方法和训练目标。
具体实现
每个文本输入都被tokenizer转化一个整数表示,图像输入则通过VAE编码为latent patch,每个patch用一个连续向量表示,按照从左到右、从上到下的顺序排列,形成每张图像的patch向量序列,并在图像前后加入BOI和EOI标记。
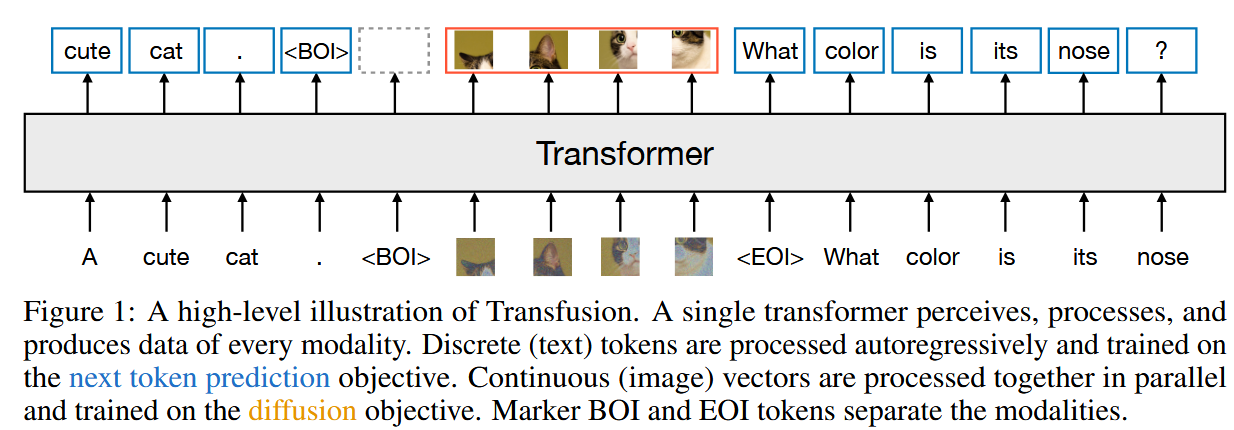
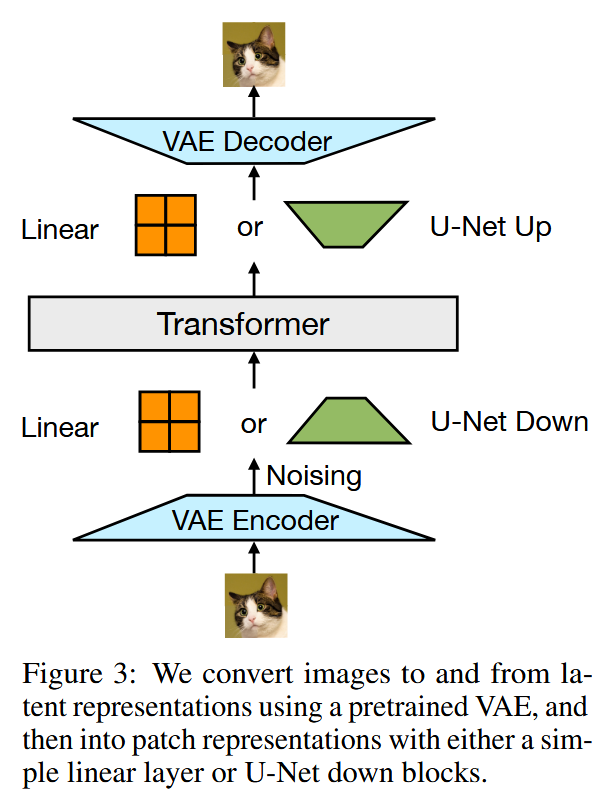
对不同模态的输入,本方法使用了独立的轻量级模块将其转换到同一向量空间中。对于文字输入离散向量使用嵌入矩阵进行转化,对于图像输入的连续向量则使用线性层或者U-Net的上下采样模块进行转换(实验证明U-Net效果更好)。
在Transformer的注意力模块中,在对序列中每个元素应用因果注意力的基础上,对所有图像元素之间应用双向注意力,使得每个图像patch可以关注同一图像中的所有其他patch,但都只能关注序列中先前出现的文本。

我们对文本和图像生成设定不同的损失函数,结合语言建模损失和噪声预测损失,最终的损失函数可记作:
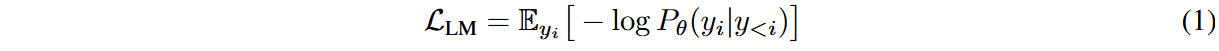
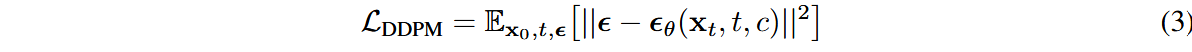
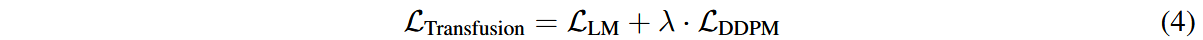
与训练目标相对应,推理时的解码步骤可分为LM和diffusion两种模式。
遇到文本输入时使用LM模式,逐步使用自回归方式预测下一个token。当遇到BOI输入时转化为diffusion模式,将以 n 个图像patch形式的纯噪声
本博客所有文章除特别声明外,均采用 CC BY-NC-SA 4.0 许可协议。转载请注明来源 由本自性清净故,令诸爱染悉无垢!
