LMFusion
LMFusion: Adapting Pretrained Language Models for Multimodal Generation阅读笔记
motivation
为了在赋予预训练LLM视觉理解和生成能力的同时,更好的保存其处理文本的性能,本方法整合了原本针对语言处理预训练的 Llama 模块,同时引入了额外专用于视觉理解和生成任务的 Transformer 模块,对不同模态使用不同的QKV投影和FFN层,并冻结处理语言模态相关模块的权重。
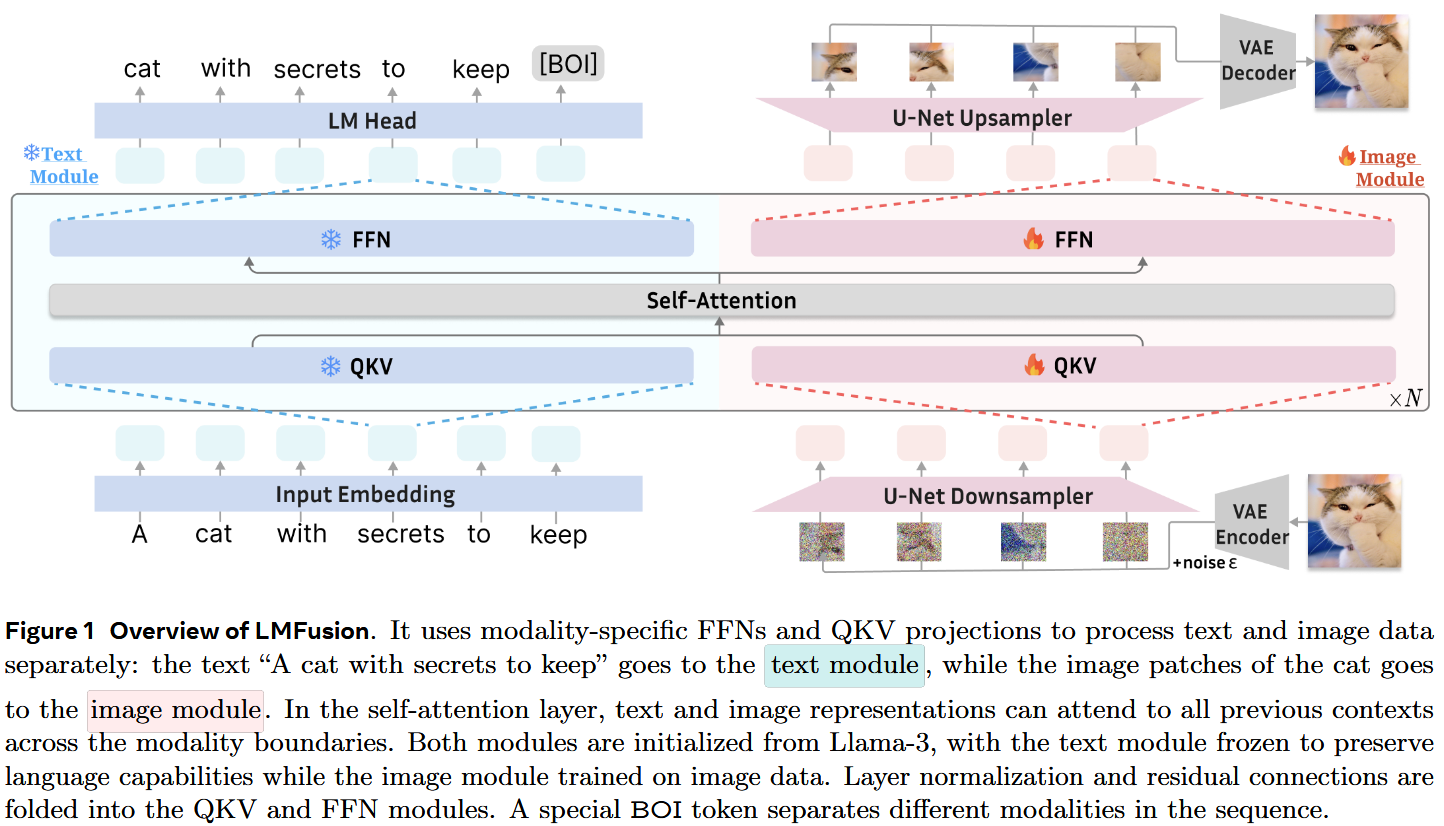
具体实现
记文本输入为

分别对不同模态的向量表示使用不同的QKV投影层并正则化:
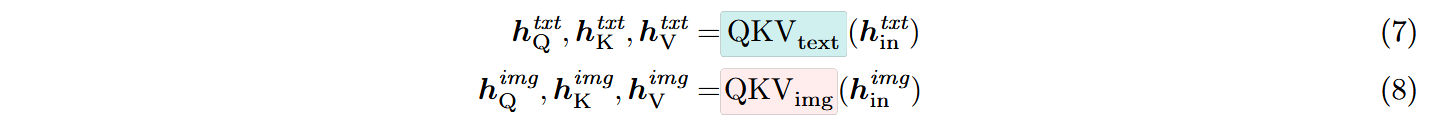
分别使用不同的O层投影和Query对拼接后的Key、Value使用注意力机制以交互不同模态间的信息,其中M 表示Transfusion的混合注意力掩码,其对文本输入应用因果掩码,对图像标记应用双向掩码:
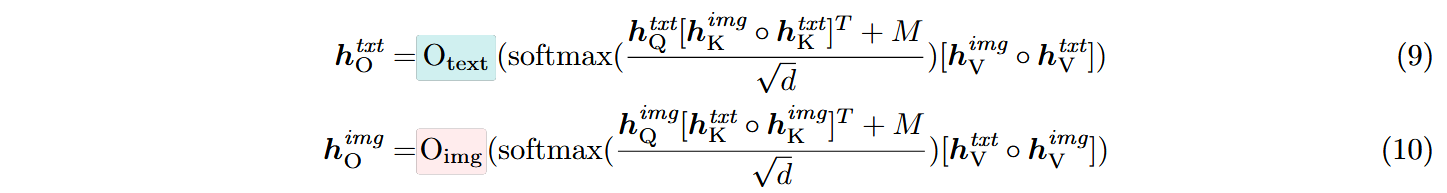
接着对不同模态的向量使用不同的FFN层:
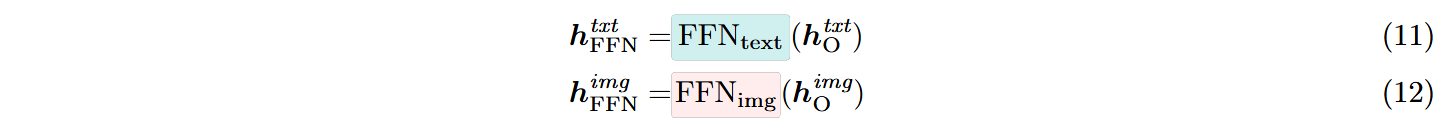
在经过N层注意力机制处理和FFN后,将语言输出映射到最终的logits,图像输出通过UNet上采样还原:

模型训练目标与Transfusion一致,但在实际训练中将文本(
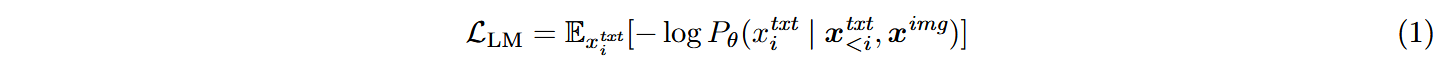
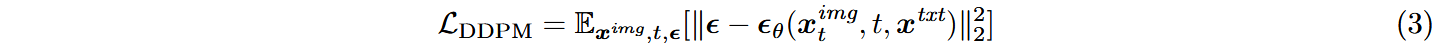
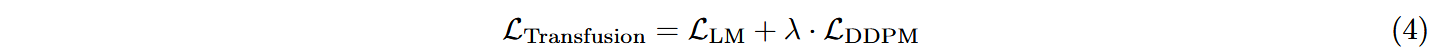
本博客所有文章除特别声明外,均采用 CC BY-NC-SA 4.0 许可协议。转载请注明来源 由本自性清净故,令诸爱染悉无垢!
