VideoDirector
VideoDirector: Precise Video Editing via Text-to-Video Models阅读笔记
motivation
现有的T2I模型直接应用到视频编辑上时,会面临颜色闪烁和内容畸变等问题。原因主要有:
- 当前Diffusion Pivotal Inversion难以分离视频生成过程中嵌入的空间和时间信息。
- 传统交叉注意力机制在保留原始内容的精细特征方面存在不足。
创新点1:基于视频重建的Pivotal Inversion
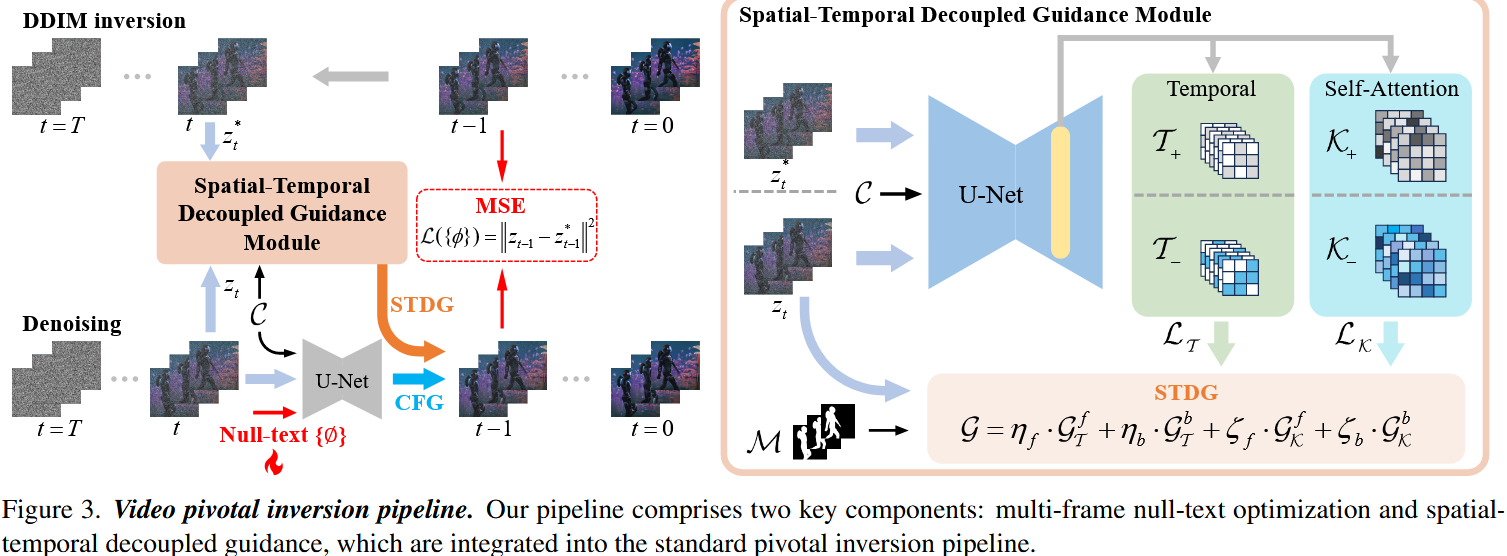
传统的空文本嵌入在所有视频帧中共享同一嵌入,缺乏对时间建模的能力,为此引入多帧空文本嵌入
传统的无分类器引导方法难以区分时间空间维度的信息,因此分别对时间和空间特征进行约束。
记$\Gamma_{+}、\Gamma_{-} \in R^{(HWC) \times F \times F}
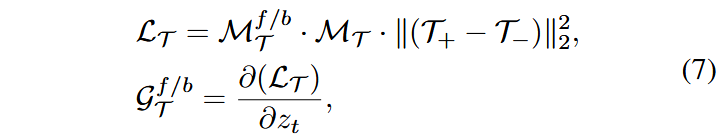
相应的,空间的约束可表示为:
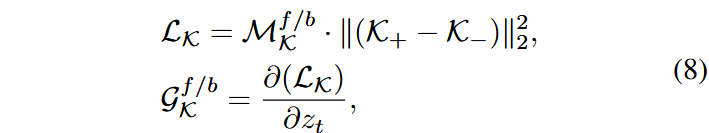
其中,
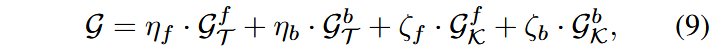
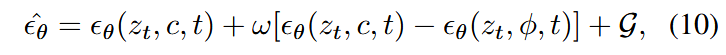
其中
创新点2:基于注意力机制的生成内容控制
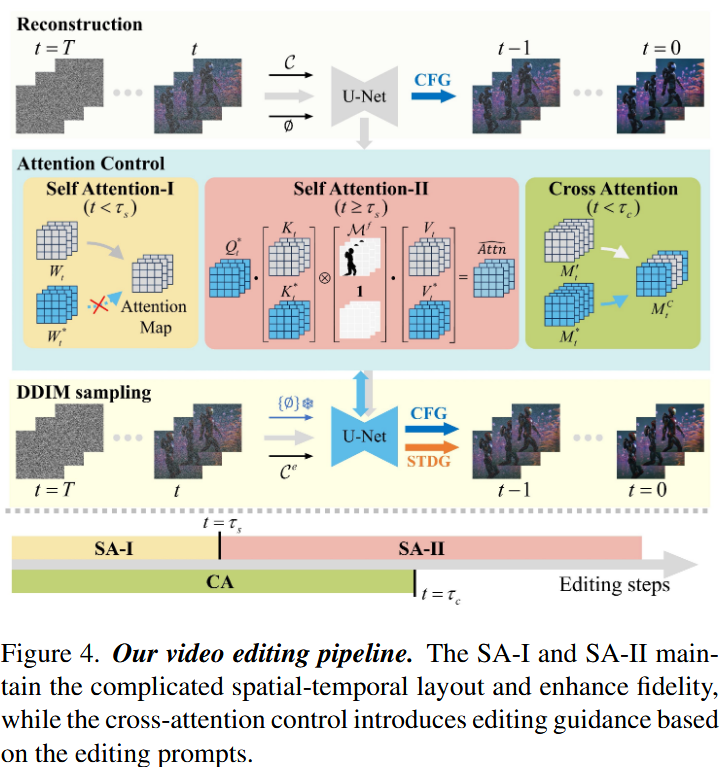
自注意力控制
在一阶段(SA-I)初始化与输入视频对齐的时空布局。在编辑开始阶段,我们在前
在二阶段(SA-II)将重建(
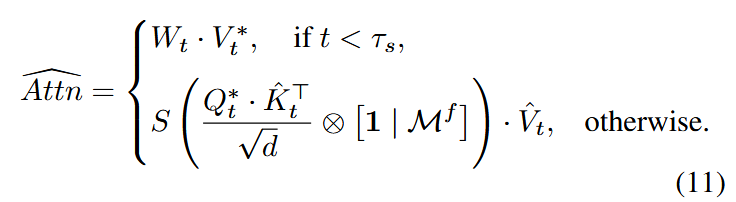
交叉注意力控制
在前
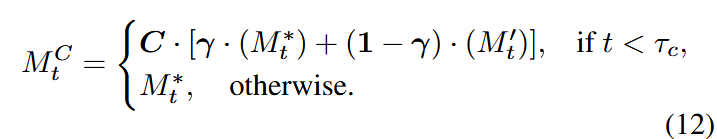
其中
本博客所有文章除特别声明外,均采用 CC BY-NC-SA 4.0 许可协议。转载请注明来源 由本自性清净故,令诸爱染悉无垢!
