RE-VDM
Repurposing Pre-trained Video Diffusion Models for Event-based Video Interpolation阅读笔记
motivation
在基于事件的视频插帧任务下第一次使用调整后的预训练video diffusion(VD)
该领域方法泛化效果不佳的两大原因:训练数据的数量和质量有限,模型高度专门化。
模块1:使用事件相机作为控制条件的适应性调整
由于EVFI数据集较小,为防止微调造成预训练VD的灾难性遗忘。本方法在训练过程中冻结VD的原始权重,同时引入基于事件的控制机制,仅训练从原始去噪网络复制的一部分块,作为额外的残差连接到原始去噪网络中的对应块输出。
优化目标是最小化预测噪声
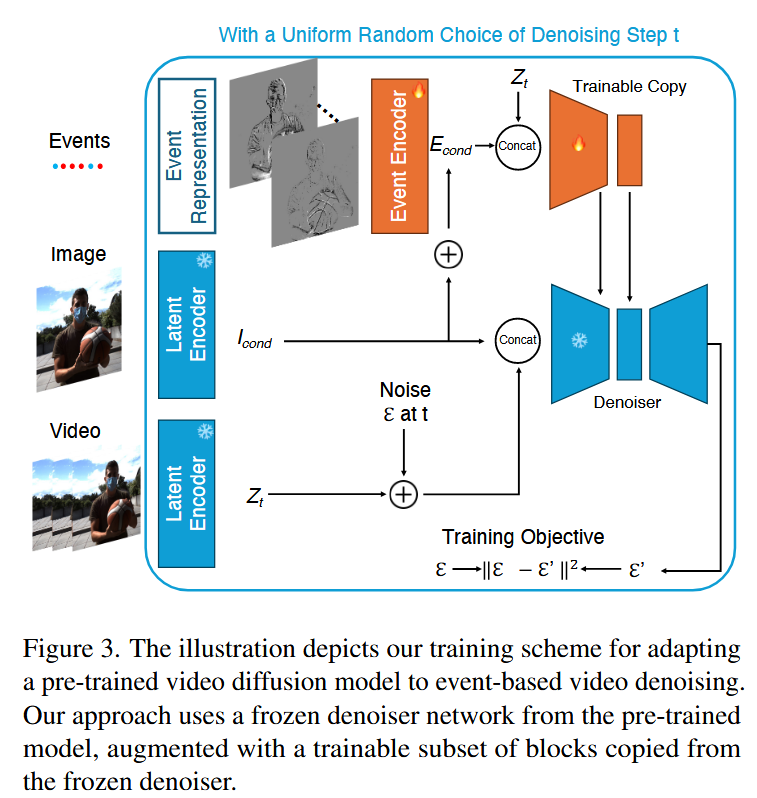
本方法使用了由一系列带步幅的卷积层组成时间编码器,能够对输入事件数据进行降采样,最终生成事件潜变量
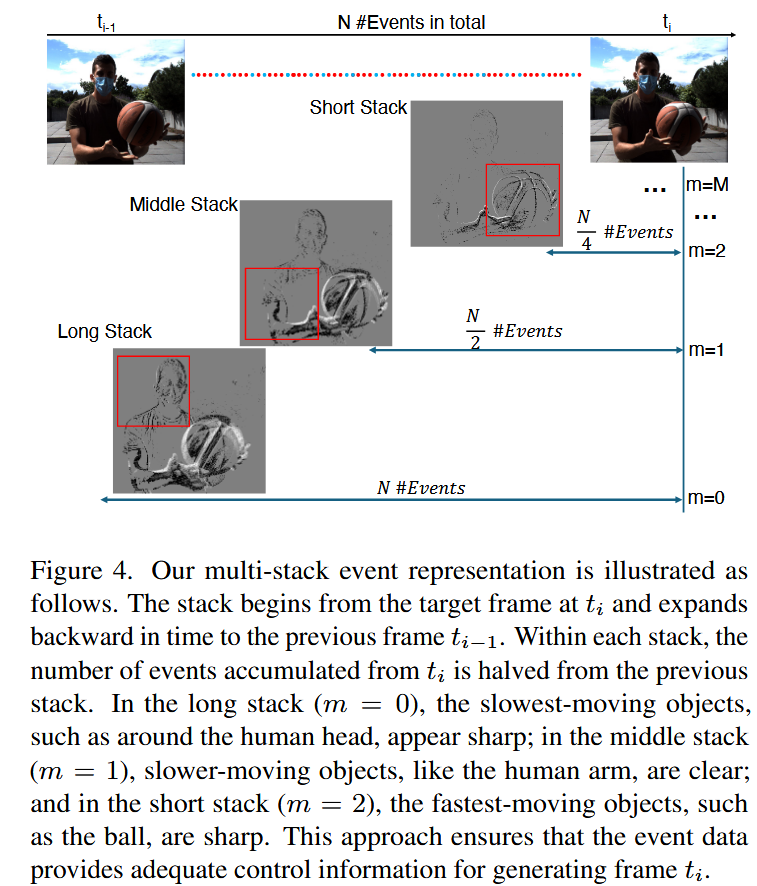
本方法使用多栈方法(multi-stack)表示事件,能够在多通道、帧状格式中捕捉快速和缓慢移动的物体,以确保丰富的时间信息被保留。
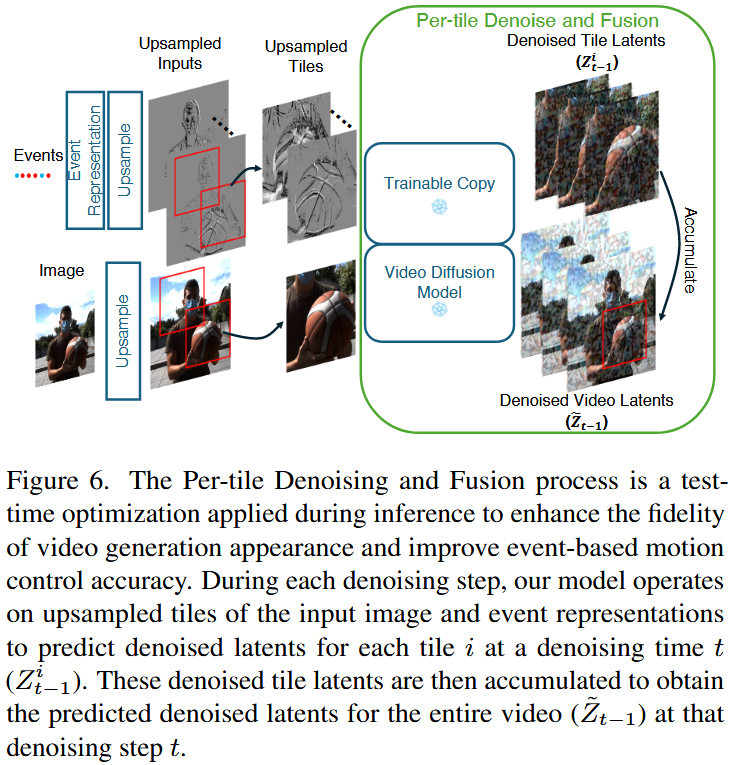
模块2:分块去噪融合
记输入的视频维度
在 VAE 编码/解码过程中,细节可能会丢失。对输入视频进行上采样虽然能缓解这个问题,但会显著增加训练和测试阶段的计算成本。
为此,我们首先将潜变量划分为
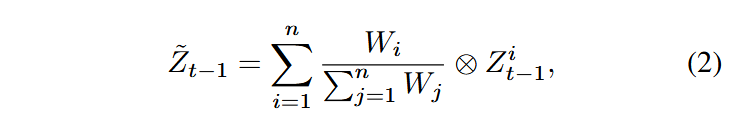
其中
模块3:从视频生成到视频插帧
视频插帧要求模型不仅利用首帧信息还需要利用到尾帧信息,本方法使用了一种测试时优化技术解决这个问题。
在每个去噪步骤中,我们分别从起始帧和结束帧结合相关的时间信息运行,生成两组预测的去噪视频潜变量。随后,我们采用双向融合方法,将这些去噪潜变量合并,以确保最终结果的一致性。
记EVDS代表结合事件信息的视频生成,
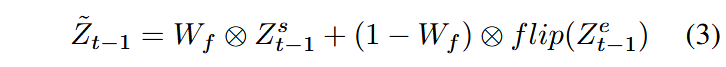
其它
训练在4张50G A6000上完成。
