vp4video-editing
Visual Prompting for One-shot Controllable Video Editing without Inversion阅读笔记
motivation
- 每一步DDIM Inversion都会带来误差,因此想提出一种不需要DDIM Inversion的One-shot controllable video editing(OCVE)方法。
- 认为OCVE和visual prompt有共通之处,都旨在在图像之间传播特定的修改,因此可将其视作一种特殊的visual prompt任务。

架构图
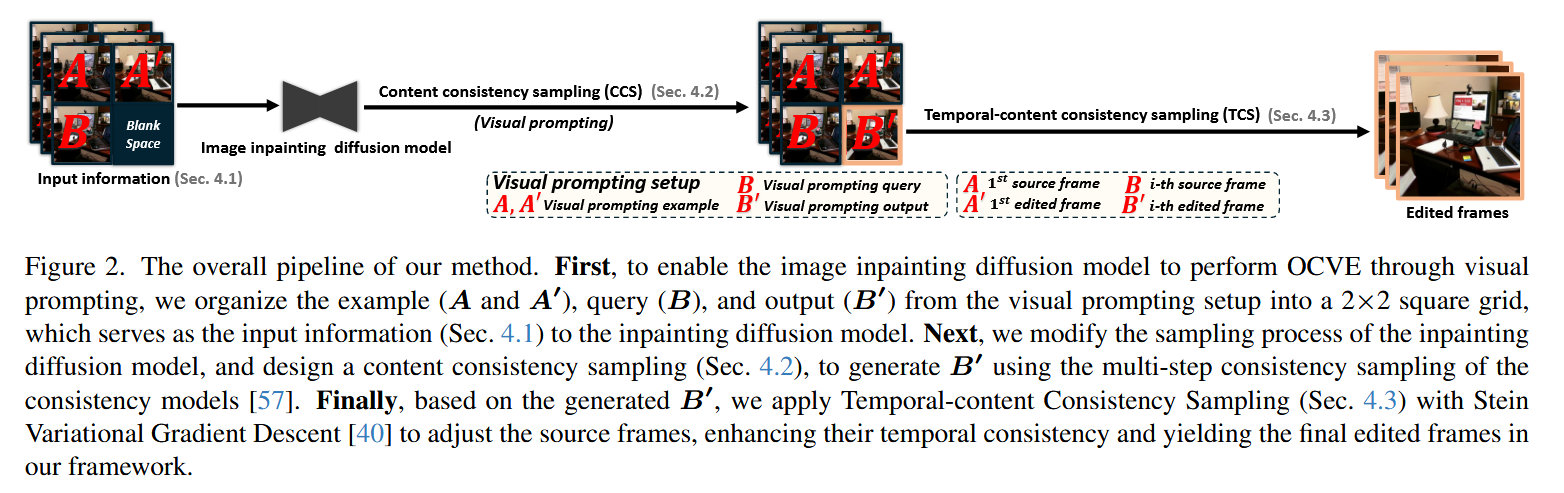
创新点1:从visual prompt的角度重构OCVE任务
在OCVE任务中扩散模型需要基于提供的一对示例帧(编辑前后的第一帧),推断如何编辑视频的后续帧。为此,本文提出利用inpainting diffusion来完成该任务,因为此类模型擅长填补图像中缺失的区域,同时保持与周围部分的上下文一致性。
inpainting diffusion的运作基于基于三个输入参数:待修复的输入信息
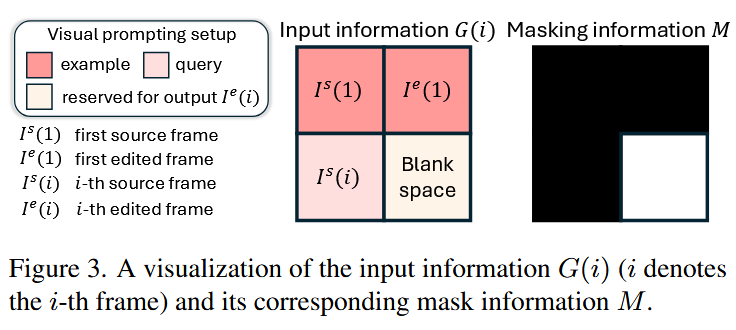
为了完成OCVE任务,本文将输入
分为四个区域。左上角为编辑前的第一帧,右上角为编辑后的第一帧,左下角为待编辑的目标帧,右下角为尚未生成的编辑后的目标帧。 掩码中的黑色为保持不变的部分,掩码中的白色表示需要inpaint的部分,即待编辑区域。
- 鉴于 CLIP 空间中的向量通常能够有效捕捉编辑方 [48],我们将用户的编辑表示为第一帧图像编辑前后在 CLIP 嵌入空间中的编码特征之差,记
为原始的第一帧, 为编辑后的第一帧, 为CLIP的图像编码器,则文本提示可表示为:
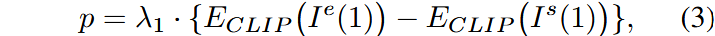
创新点2:内容一致性采样(CCS)
由于我们的方法未采用 DDIM 反演,为了确保生成的编辑帧与源帧之间的内容一致性,本文从一致性模型的采样中获取了灵感,提出了一种基于inpainting diffusion模型的多步一致性渐进式去噪采样。
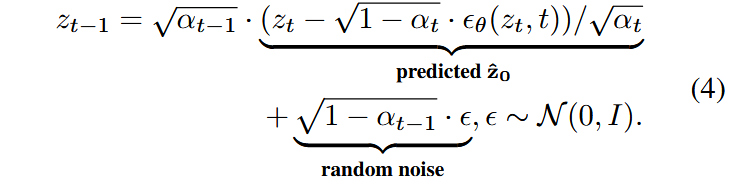
原始的inpainting diffusion去噪过程为:

为了去除去噪过程对于马尔可夫链的依赖,记
为了确保多步一致性,无论在什么时间步下,预测出的
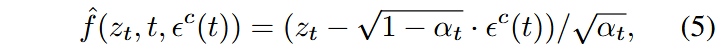
记
将上式带入原始的去噪过程,可得:
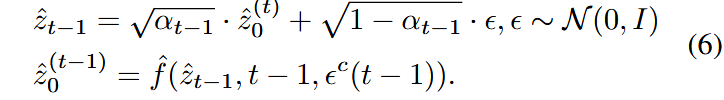
本方法希望源帧开始,逐步沿着用户设定的编辑方向调整内容,最终生成期望的编辑帧,同时保持与源帧的内容一致性。因此认为设定 CCS 在第一个时间步生成源帧,即
用户编辑在潜空间带来的噪声变化可视作:
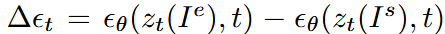
一致性模型的预测过程变为:
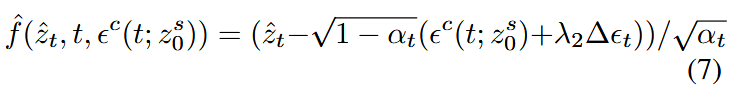
创新点3:时间一致性采样(TCS)
为了保持视频的时间一致性,本文视频视为一个分布,其中的每帧的潜变量被视为从该分布中抽取的样本,记作
本方法采用一个
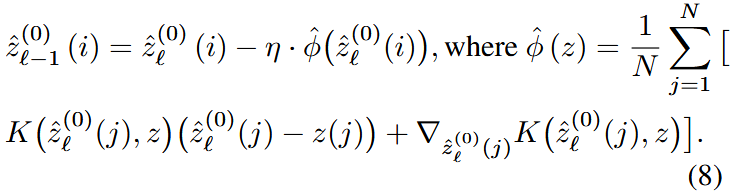
其中
