Mimir
Mimir: Improving Video Diffusion Models for Precise Text Understanding阅读笔记
motivation
- 当前基于文本编码器理解提示信息的视频扩散模型在文本理解方面仍然存在局限性。
- 人类提供的简短提示无法捕捉视频中广泛的细节。
- LLM更注重预测接下来的文本,而非理解给定的文本,阻碍了LLM在现有T2V模型中的直接应用。
前置:输入解析
记输入的视频为
对于文本提示T进行两种处理:
- encoder branch:使用诸如T5的文本编码器对其编码得到
。 - decoder-only branch:将T输入如Phi-3.5的大语言模型,得到其所有的query token和answer token记为
,同时根据给定的四个提示生成相应的指令token 。
架构
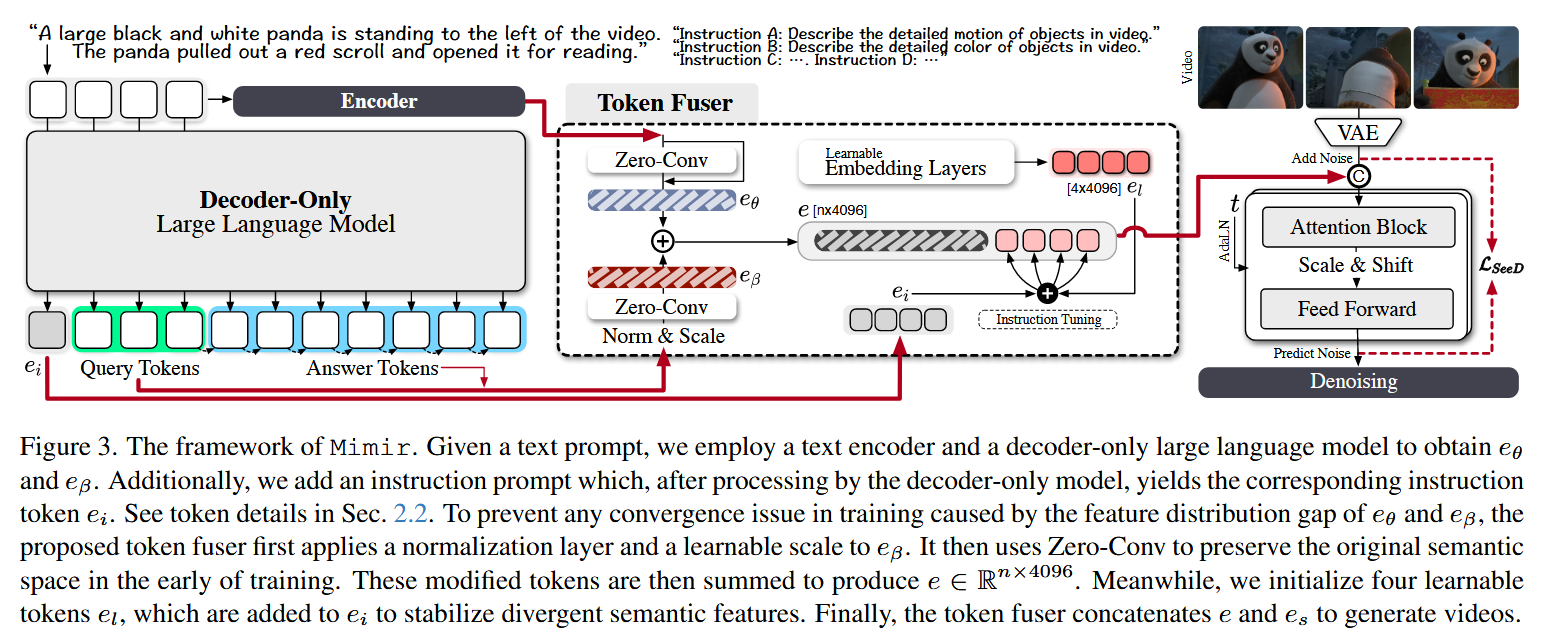
创新点1:Non-Destructive Fusion
该模块的主要目的是对encoder branch和decoder-only branch解析完的本文提示进行融合,从而充分运行大语言模型推理能力并丰富文本提示细节。
在decoder-only分支的LLM之后插入一个可学习的归一化层,将两种文本标记对齐相似的尺度。归一化层后插入零卷积层
在encoder分支的编码器输出后以残差方式插入一个零卷积层
通过加权相加的方式得到融合后的语义向量
创新点2:Semantic Stabilizer
其核心功能为确保去噪模型能够准确捕捉提示中的关键语义元素,稳定在next token prediction过程中出现的波动性文本特征。
预先定义四条指令,送入LLM后生成指令token
将
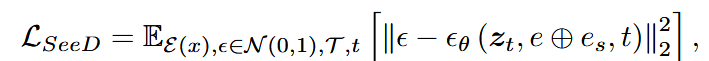
本博客所有文章除特别声明外,均采用 CC BY-NC-SA 4.0 许可协议。转载请注明来源 由本自性清净故,令诸爱染悉无垢!
