VideoDPO
VideoDPO: Omni-Preference Alignment for Video Diffusion Generation阅读笔记
motivation
针对 T2V 数据质量的评估,可以从视频质量和语义对齐两个维度展开。由于视觉质量与语义对齐之间的相关性较低,同时视觉质量中的各个细分指标之间也缺乏较强的关联性,因此需要一种能够同时囊括这两个方向的综合评分标准。
部分正负样本间的差异较小,模型在对比学习时应更多关注那些差异显著的样本对。
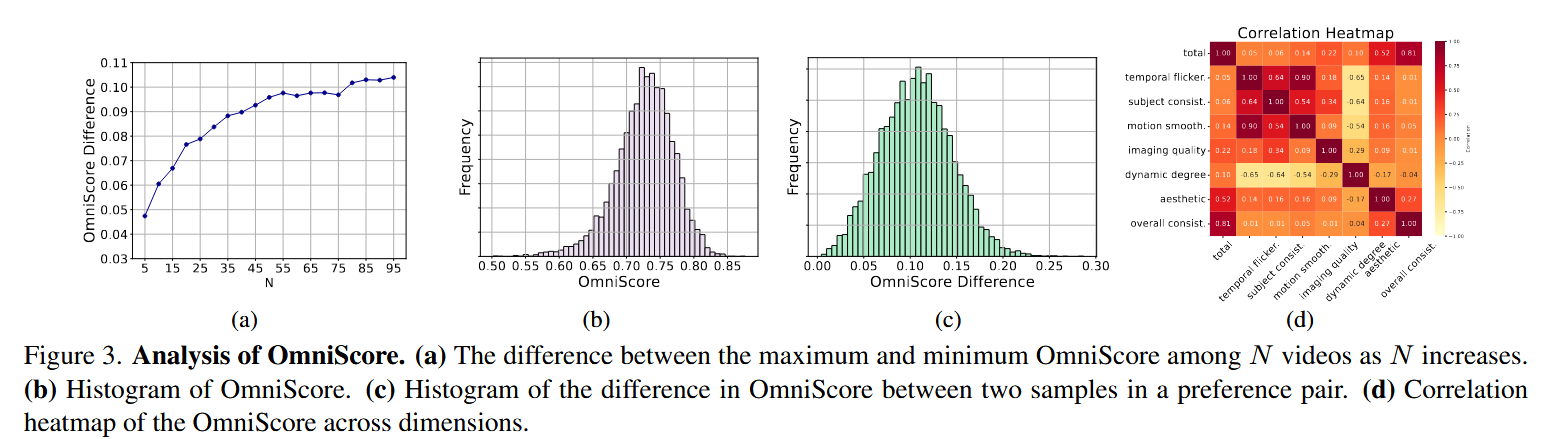
总体架构
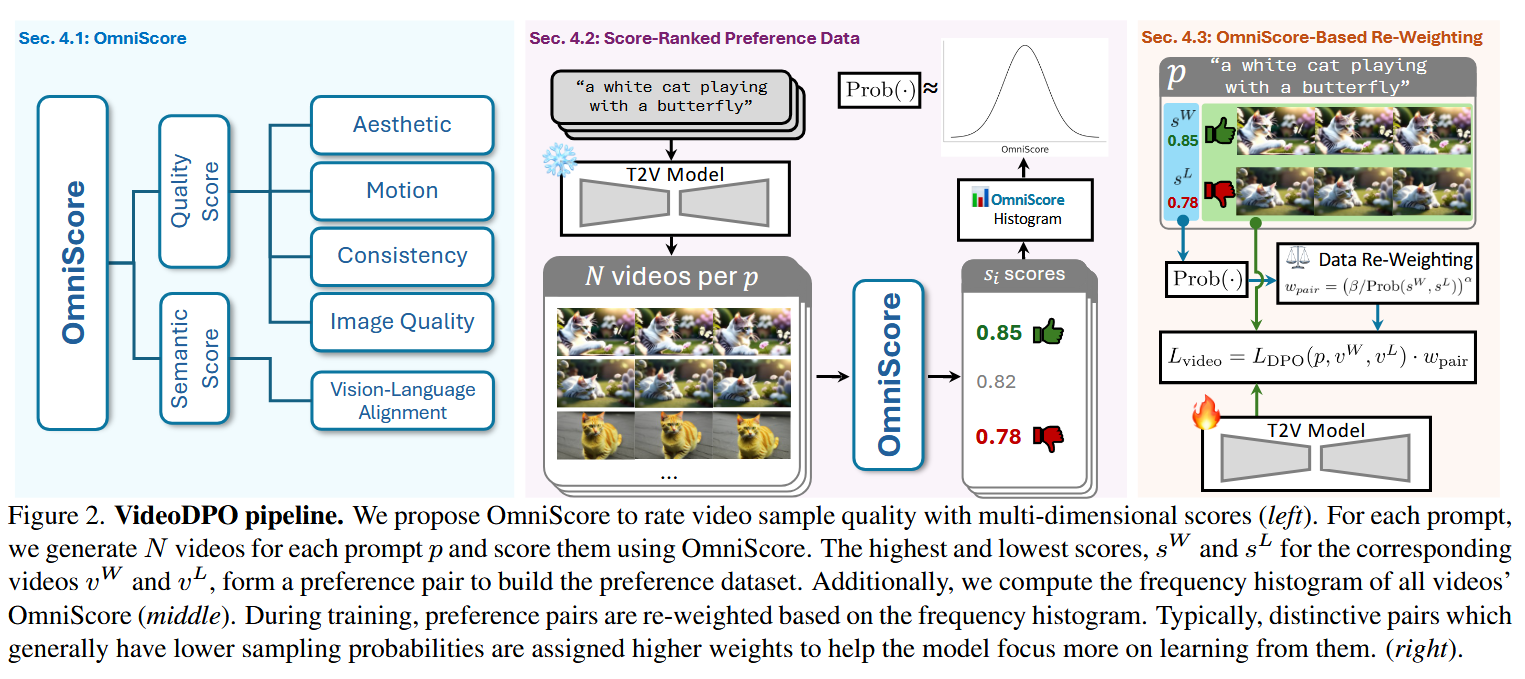
创新点1:OmniScore
为了同时评估视频质量和语义对齐,本文提出了Omniquant,从帧内质量、帧间质量以及语义对齐度三个方向进行评估。
对于不同的评估方向使用不同的指标和模型进行评估,评估后将其每个维度缩放到
对于运动平滑度,使用Amt(一个视频插帧模型)的运动先验判断;对于物体连贯度,计算跨帧的 DINO 特征相似度;对于时间闪烁程度,使用RAFT得到静态帧后计算帧间的绝对值差的平均;对于动态程度,也使用RAFT评估;
对于图像质量,使用在 SPAQ 数据集上训练的 MUSIQ 图像质量预测器对其进行评估;对于美学价值,使用LAION 预测器评估。
对于语义对齐程度,使用由 ViCLIP 计算的视频文本一致性 评估。
创新点2:基于OmniScore的训练样本构造与加权
记给定的文本提示为
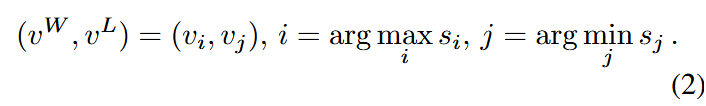
一些正向与负向样本之间的得分差异可能极小,对模型训练的用处较小,我们建议对那些区分度更明显的偏好对赋予更高的权重,从而使模型聚焦于能够提供更具意义对齐提示的样本对。
记共有
对于每个正负样本对,记其概率为
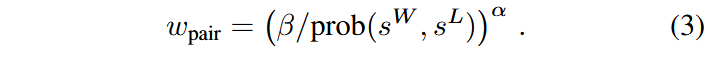
其中
最终的训练损失函数为: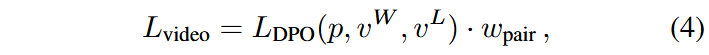
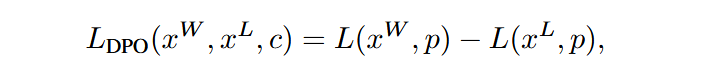
其它
如果直接从训练样本中剔除得分差异小的样本对,性能反而会降低,这可能是因为移除这些样本对(包括相应的提示)降低了训练数据的多样性。
