ARTV
ART·V: Auto-Regressive Text-to-Video Generation with Diffusion Models阅读笔记
motivation
- 认为递归式的基于前一帧生成下一帧只需要模型学习相邻帧间的运动即可,比长距离运动学起来更简单。
- 对原始T2I模型改动较小,能够保留其高保真的生成能力。
- 让模型更多的从参考图像中提取信息,而不是完全依赖于去噪过程。
模块1:结合掩码的扩散模型(MDM)
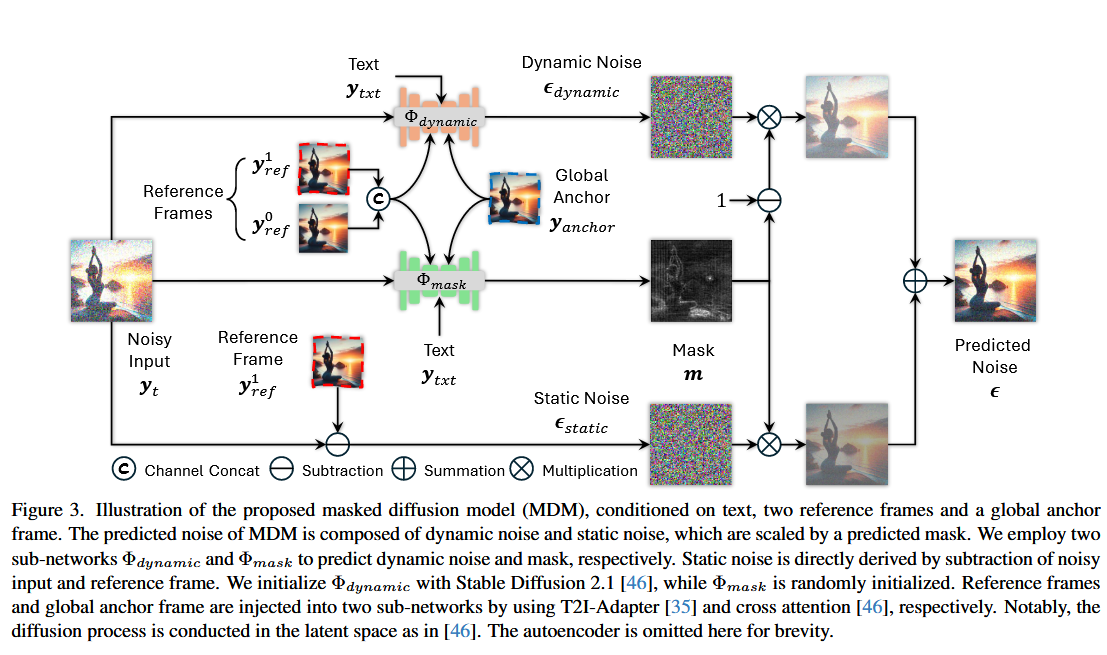
将待生成帧的前两帧作为参考帧
记参考帧为
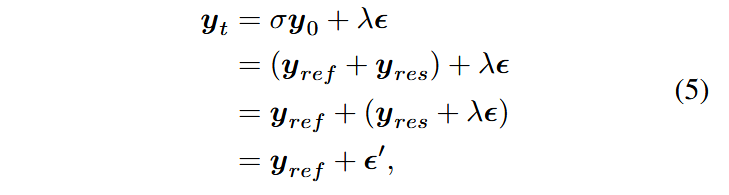
联立收尾两行得:
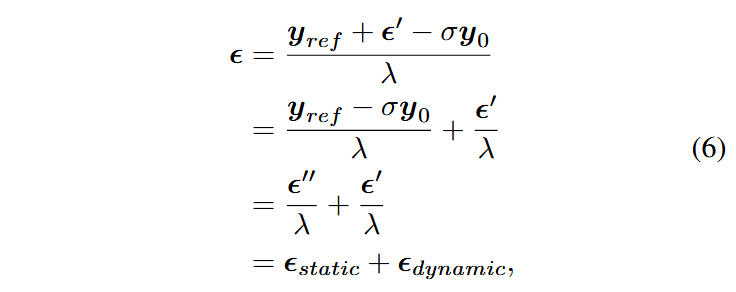
本文将
利用
最终MDM的输出可表示为:
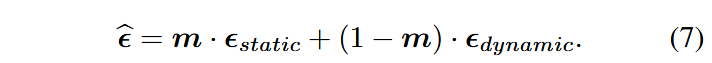
模块2:噪声增强
由于模型的训练与测试数据间有差异,测试时使用的参考帧是模型生成的,相比于ground truth还是会含有更多噪声,因此在训练过程中随机想参考帧和锚帧中加入噪声。
随机选取噪声等级
还将噪声水平
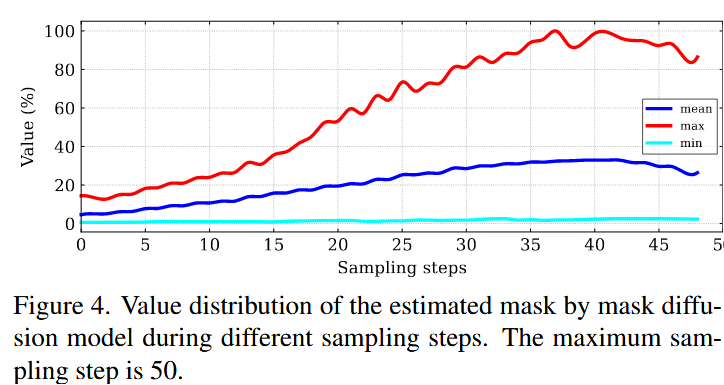
模块3:锚帧调节
为了增强长视频中的物体和场景的一致性,使用锚帧进行调节。
训练中随机从固定的时间窗口前选取一帧,测试时选取第一帧作为锚帧
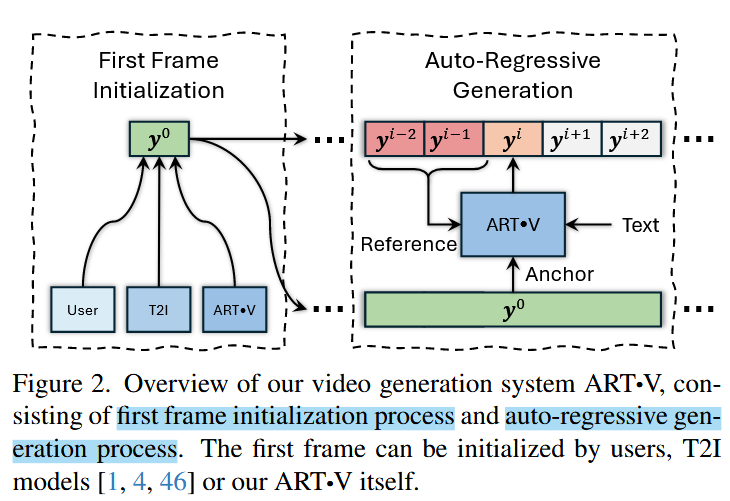
其它
在训练时以10%的概率随机丢弃视频生成的控制条件。
本博客所有文章除特别声明外,均采用 CC BY-NC-SA 4.0 许可协议。转载请注明来源 由本自性清净故,令诸爱染悉无垢!
