Dysen-VDM
Dysen-VDM: Empowering Dynamics-aware Text-to-Video Diffusion with LLMs阅读笔记
motivation
当前的T2V生成任务存在较低的帧数,不流畅的视频过渡,粗糙的视频运动,以及混乱的动作等问题。
- 语言提及的一系列动作可能并不严格符合物理上的实际发生顺序,因此,正确组织事件的语义时序至关重要。
- 提示文本不可能涵盖所有动作场景,需对其合理丰富。
- 上述过程应使用结构化的语义表示。
- 应实现细粒度的时空特征建模,从而确保视频生成在时间上的连贯性。
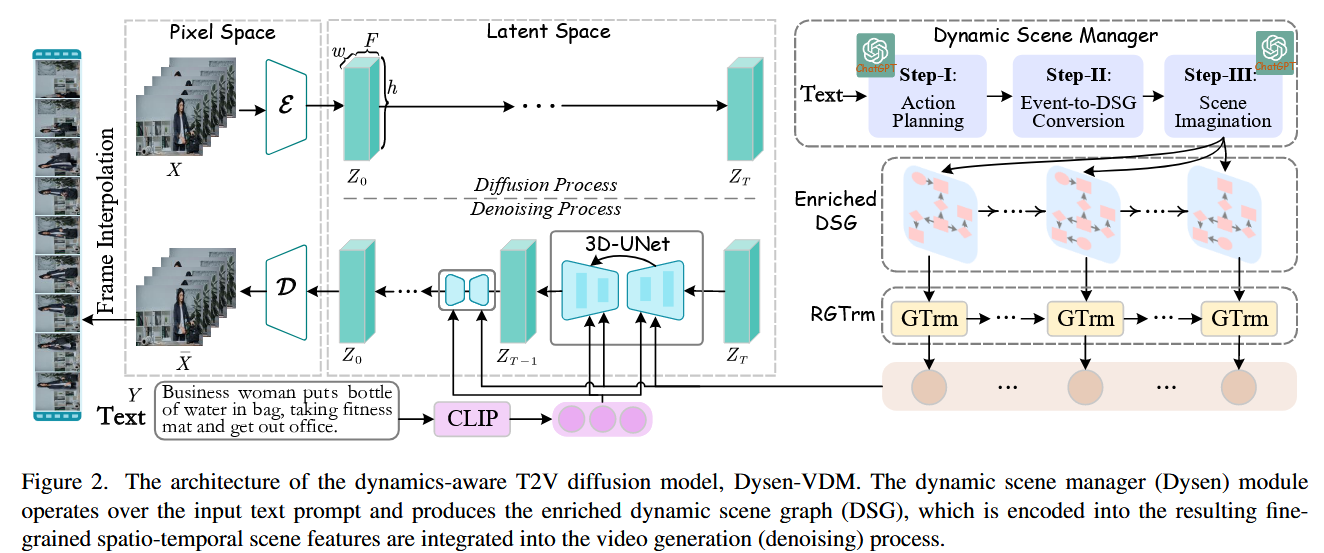
创新点1:动态场景管理器
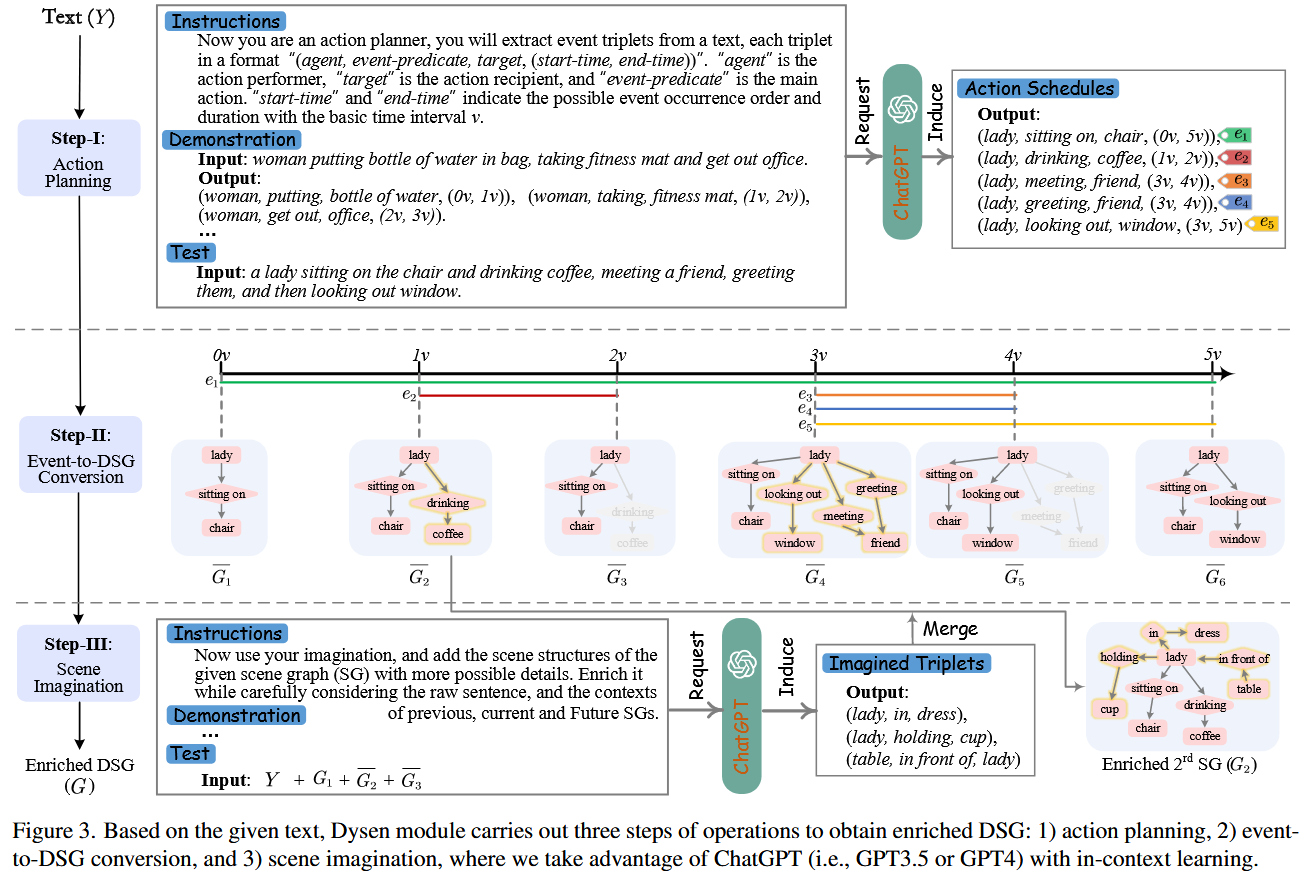
阶段1:动作规划
使用ChatGPT利用上下文学习使其根据文本提示输出任务规划,形式为 “(agent, event-predicate, target, (start-time, end-time))”,以原子时间
阶段2:动态场景图生成
根据动作规划为每一帧生成一个场景图。 场景图包含对象、属性和关系三种类型的节点,其中一些场景对象通过特定的关系相互连接,构成了空间语义三元组 “subject-predicate-object”。
阶段3:动作场景丰富
该阶段分两轮进行。记阶段2生成的动态场景图为
创新点2:场景信息融合
本文使用recurrent graph Transformer (RGTrm)进行场景信息融合。
记RGTrm有L层,每个场景图要经历M次递归,场景图
记k表示注意力头的编号,每个头的QKV可使用
连接结点
则每条边对应的权重可计算为:
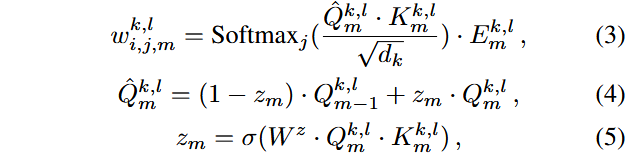
记
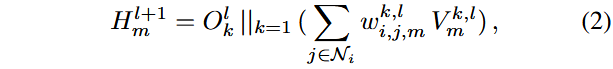
最终得到动态场景图表示
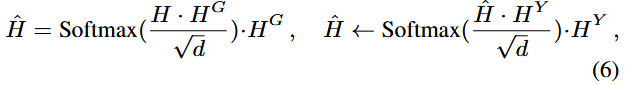
其它
首个尝试利用大型语言模型来进行动作规划和场景想象。
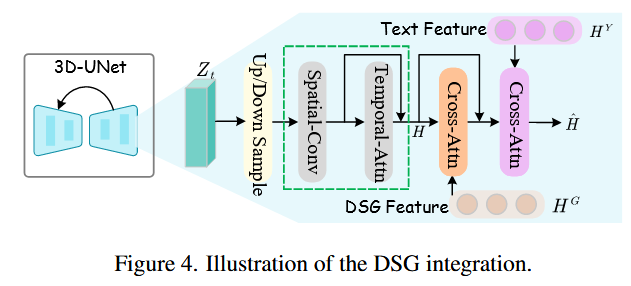
整体架构:
本博客所有文章除特别声明外,均采用 CC BY-NC-SA 4.0 许可协议。转载请注明来源 由本自性清净故,令诸爱染悉无垢!
