MultiDiffusion
MultiDiffusion: Fusing Diffusion Paths for Controlled Image Generation阅读笔记
motivation
用户对于生成图像的内容的控制以及对新任务的适应一直是T2I领域的难题。
本文旨在利用预训练的T2I模型,在不微调的情况下用一个统一的框架应对多种图像生成任务。
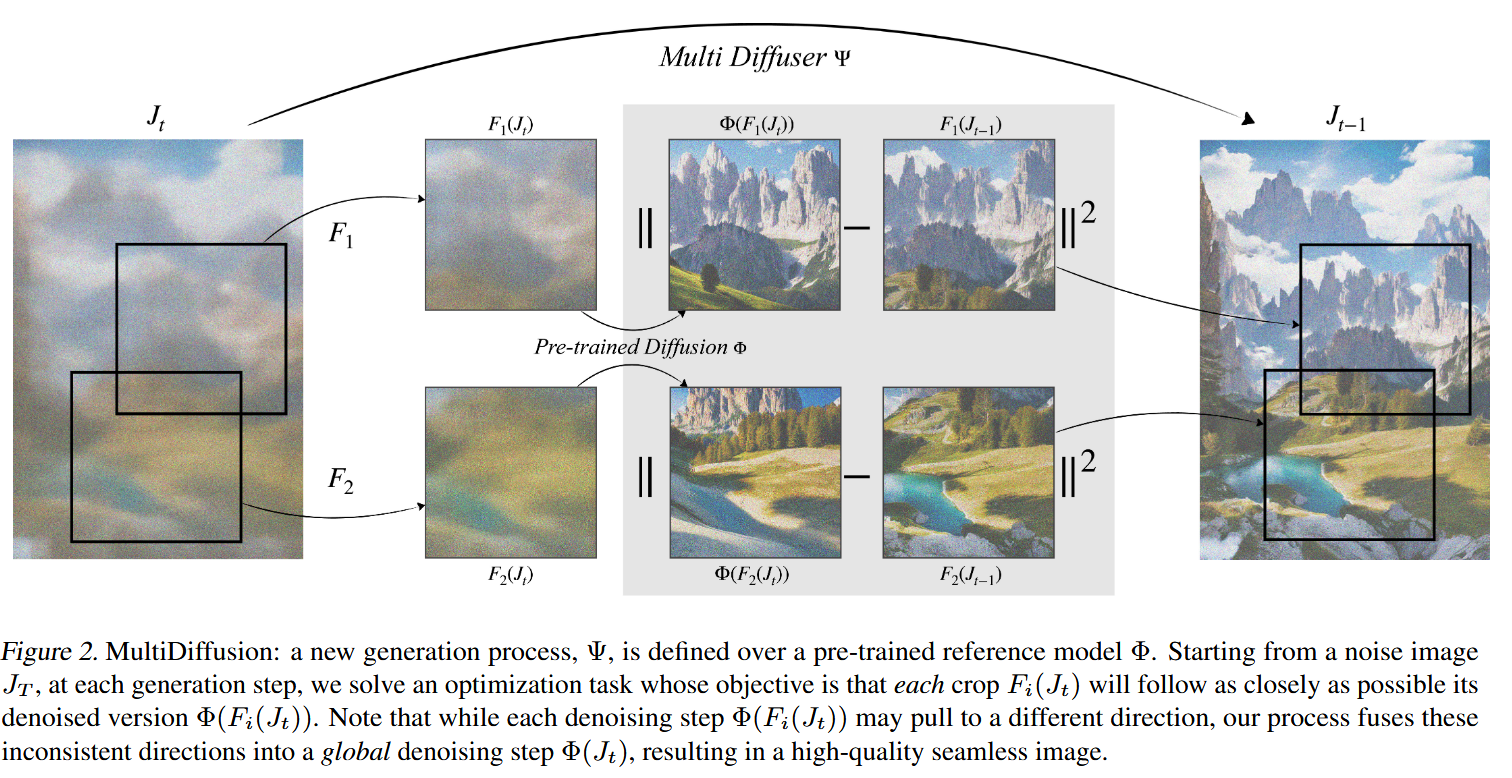
MultiDiffusion方法
记预训练模型为
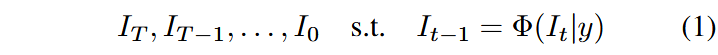
新任务要在条件空间
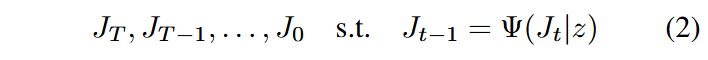
记从目标图像空间到原图像空间的映射为
本方法和底层目标为希望本方法的每一步去噪与原始模型的去噪尽可能相近,当下述FTD损失为0时,在每个时间步中,局部区域的结果
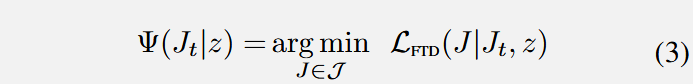
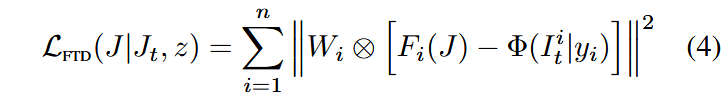
当
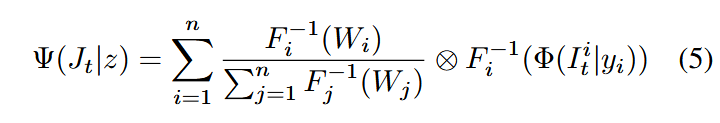
伪代码:

本博客所有文章除特别声明外,均采用 CC BY-NC-SA 4.0 许可协议。转载请注明来源 由本自性清净故,令诸爱染悉无垢!
