Lumiere
Lumiere: A Space-Time Diffusion Model for Video Generation阅读笔记
motivation
- 现有的时间超分辨率(TSR)模型先生成远距离关键帧,再插帧成视频,造成高频运动的混叠现象。
- 级联训练方案通常会受到domain gap的影响,其中TSR模型在训练时使用的是真实的下采样视频帧,但在推理时却用于生成插值的帧,这会导致误差累积。
创新点1:时空U-Net(STUNet)
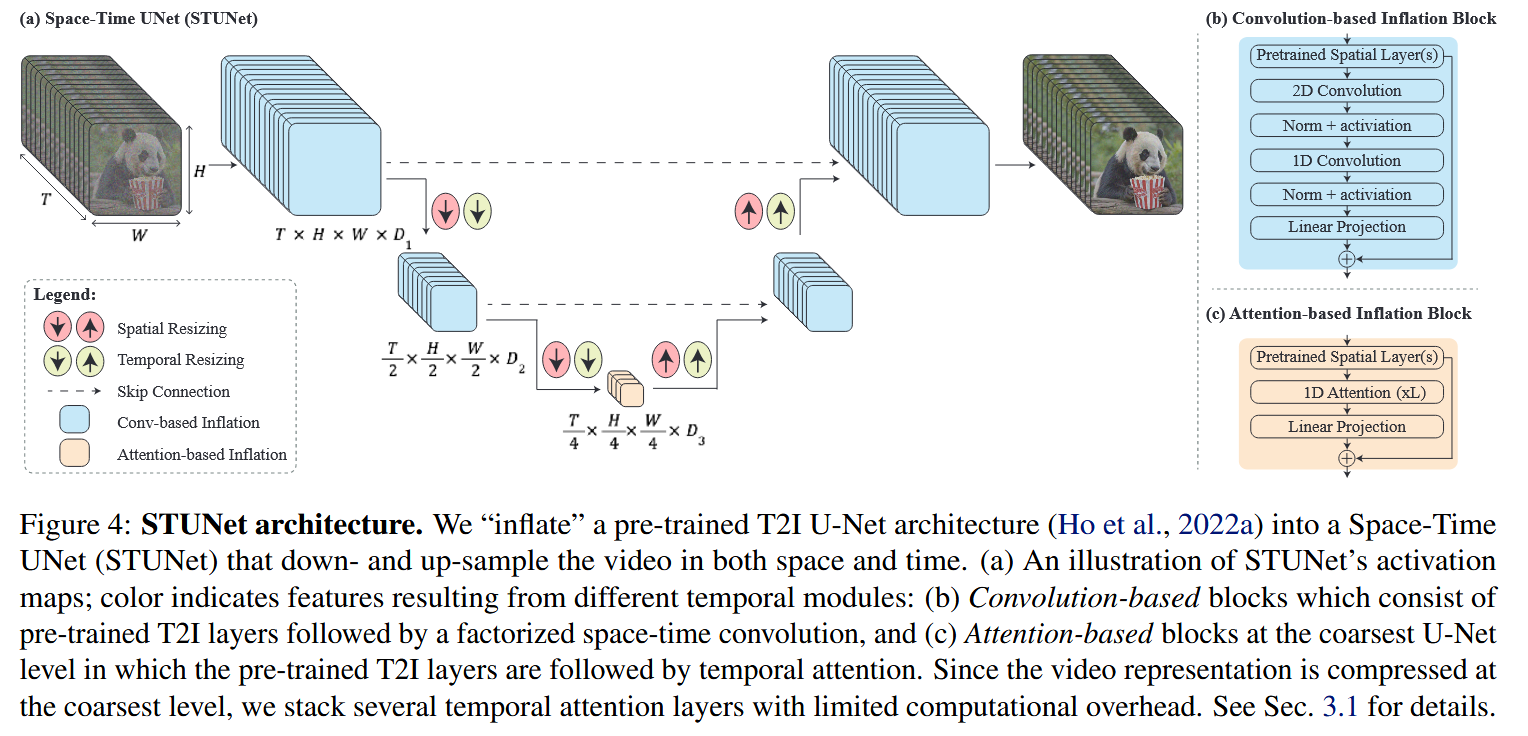
在原始U-Net中加入时间处理模块:
- 在除了最粗粒度(最中间)外的所有层中加入分解的时空卷积。其将原始的3D卷积分解成一个空间的2D卷积和时间的1D卷积,在降低计算成本,提高模型的表达能力。
- 在最粗粒度的层中加入时间注意力层,由于时间注意力的计算需求随帧数呈二次增长,在低维特征图上操作使我们能够在堆叠多个时间注意力块的同时保持较低的计算开销。
常见的时间维度扩充方法确保在初始化时,T2V模型等效于预训练的 T2I 模型,然而,本文由于时间下采样和上采样模块的存在,这一特性无法完全满足。
我们通过实验发现,如果在初始化时让这些时间模块执行最近邻的下采样和上采样,即下采样时只使用原始视频中的帧,上采样时复制已有帧,可以得到较好的初始化起点。
创新点2:在空间超分辨率任务中应用Multidiffusion
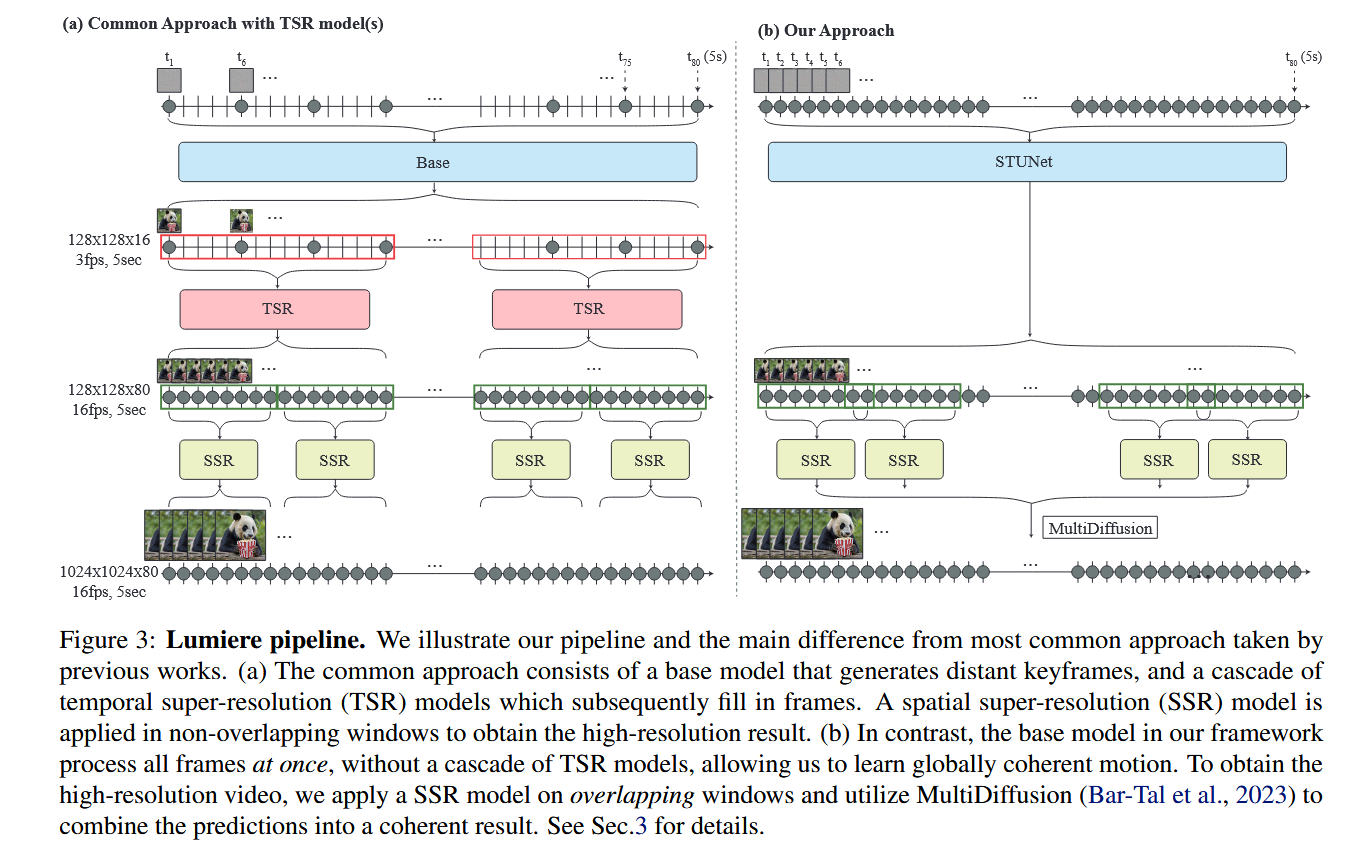
为了避免时间边界伪影,在时间维度上的边界上应用Multidiffusion。
记原始用于生成视频的噪声为
通过最小化SSR后的视频片段与生成视频间的差距对相关模块进行优化:
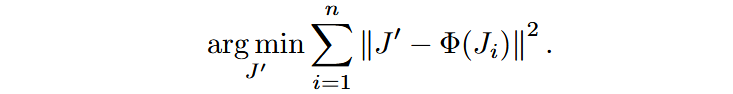
其它
在进行Stylized Generation的时候,直接用针对特定风格定制的 T2I 模型权重替换原始 T2I 权重虽然可以生成目标风格的视频,但是会出现失真或静态帧。因此,我们使用线性插值融合微调后的 T2I 权重
本博客所有文章除特别声明外,均采用 CC BY-NC-SA 4.0 许可协议。转载请注明来源 由本自性清净故,令诸爱染悉无垢!

