DreamBooth
DreamBooth: Fine Tuning Text-to-Image Diffusion Models for Subject-Driven Generation阅读笔记
motivation
现有T2I模型缺乏模拟参考图像中物体外观的能力,并且无法在不同的上下文中生成不同该物体的图像。

整体架构
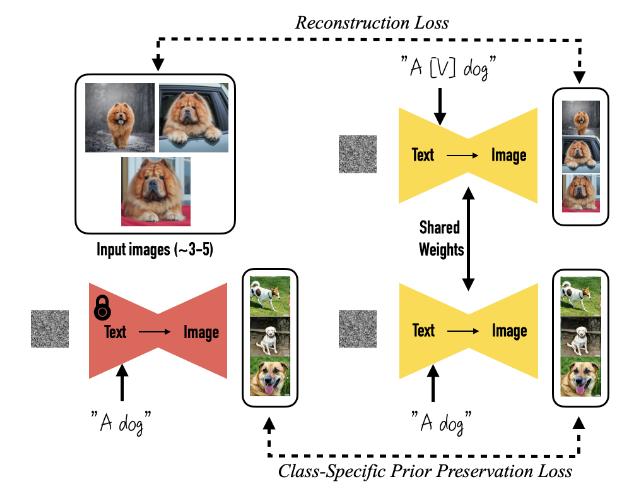
创新点1:绑定类别实例与唯一标识符
为了避免为给定的图像集撰写详细的图像描述所带来的额外工作,本文选择了一种更简单的方法,将所有输入图像标注为 “a [identifier] [class noun]”,其中:
- identifier:是与该主体绑定的唯一标识符。
- class noun:该主体的粗略类别描述(例如 cat、dog、watch 等),可由用户提供或者分类器判别得到,从而利用模型对特定类别的先验知识。
现有的英语单词通常效果不佳,因为模型需要学习将它们与原始含义解耦,然后重新绑定它们以指代我们的主体。因此,本文在词汇表中寻找稀有标记,然后将这些标记反转回文本空间,以最小化标识符具有强先验的概率。
创新点2:特定类别的先验保持损失
本文选取了微调所有层的方法,为了避免language drift(模型错误地将特定实例与类别绑定,生成的图像逐渐丧失类别特征)和输出多样性减少的问题,使用模型自身生成的样本对其进行监督,以便在少样本微调开始后,模型仍能保留原始先验知识。
记住T2I模型为
使用未微调过的原始模型采样出噪声
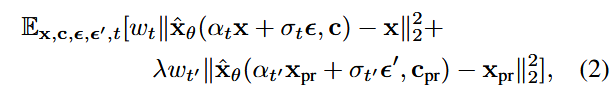
其中第一项用于衡量模型生成的图像
其它
对于一些出现概率较低的情况无法很好的生成相应提示中的上下文;物体外观保持仍有不足;对于一些与训练集相近的提示仍有过拟合现象。
只需3-5张图像即可完成微调。
本博客所有文章除特别声明外,均采用 CC BY-NC-SA 4.0 许可协议。转载请注明来源 由本自性清净故,令诸爱染悉无垢!
