AnimateDiff
AnimateDiff: Animate Your Personalized Text-to-Image Diffusion Models without Specific Tuning阅读笔记
motivation
- 解决个性化 T2I 动画生成的问题,同时保持其视觉质量和预训练模型中相关领域的知识。
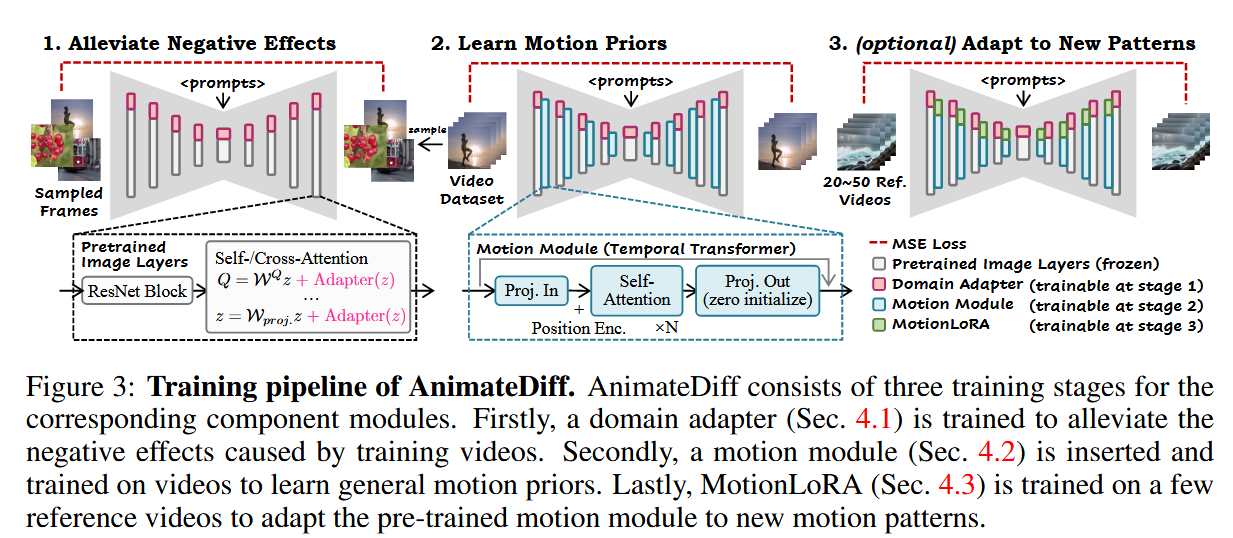
创新点1:域适应器
由于视频数据集的质量远低于图像数据集,为了避免因数据质量较低而影响训练效果,本文在基础 T2I 模型的自注意力层和交叉注意力层中引入 LoRA 领域适配器,以提升模型的适应性和生成质量。
加入域适应器后,注意力层的投影变为:
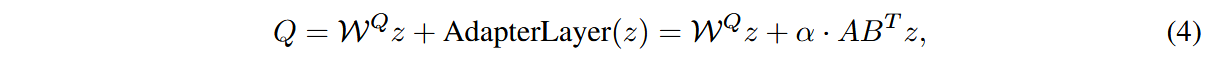
在推理时,将
创新点2:即插即拔的运动模块
T2I到T2V
视频向量维度为
在将视频向量输入本文提出的运动模块前,将其变换为
运动模块构建
将变换后的视频向量沿着时间维度分割得到
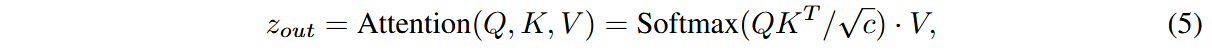
创新点3:MotionLoRA
为了使得运动模块能够处理新的运动,在运动模块的自注意力层中加入LoRA,并在新运动参考视频上训练LoRA。在20-50个参考视频上训练2000轮即可。
本博客所有文章除特别声明外,均采用 CC BY-NC-SA 4.0 许可协议。转载请注明来源 由本自性清净故,令诸爱染悉无垢!
