Text2Video-Zero
Text2Video-Zero: Text-to-Image Diffusion Models are Zero-Shot Video Generators阅读笔记
motivation
提出了“零样本文生视频”任务,在不经过进一步微调或者优化的前提下,只利用预训练的文生图模型生成视频。
整体架构:
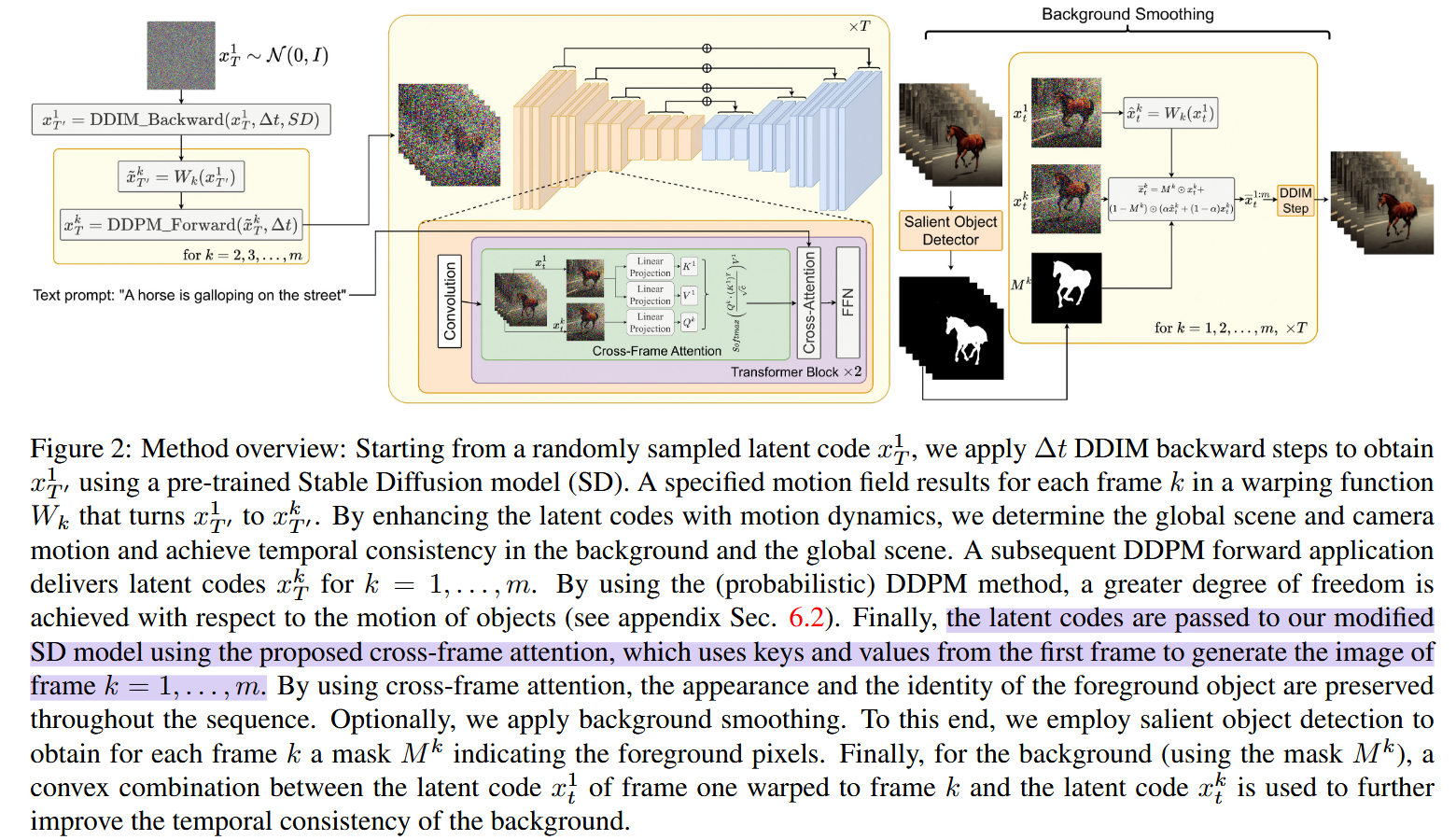
创新点1:在潜变量中融入运动信息
- 如行1,随机初始化第一帧的潜变量。
- 如行2,对第一帧
使用Stable Diffusion进行 步去噪,得到 。 - 初始化全局场景和摄像机运动方向
。 - 如行4,对每一帧计算其全局变换向量
。 - 如行5,根据
生成相应的变形操作 ;如行6,对 施加变形操作得到 。 - 如行7,对得到的
进行 步加噪得到 。 - 对
实行去噪,并生成视频。

创新点2:跨帧注意力
为了解决初始潜变量约束性不足,导致是在前景对象的时间一致性弱的问题,将每层的自注意力模块都换成跨帧注意力模块,让每帧在关注自己之外还要关注第一帧。
即: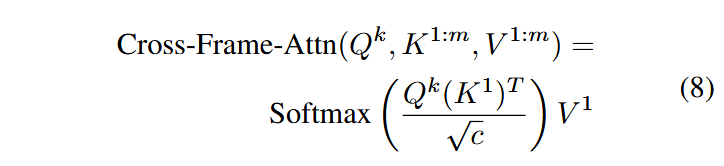
其中,
创新点3:背景平滑化
该模块是为了增强背景的时间一致性,特别针对没有提供初始图像的文生视频任务。
- 对于生成的视频序列
,通过目标检测获得每帧 的前景掩码 。 - 对第一帧使用创新点1中生成的运动变形操作
进行变形: - 对背景中的物体的潜变量使用凸线性组合进行平滑化:
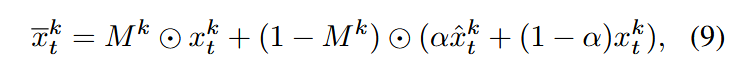
- 再对
进行去噪和视频生成。
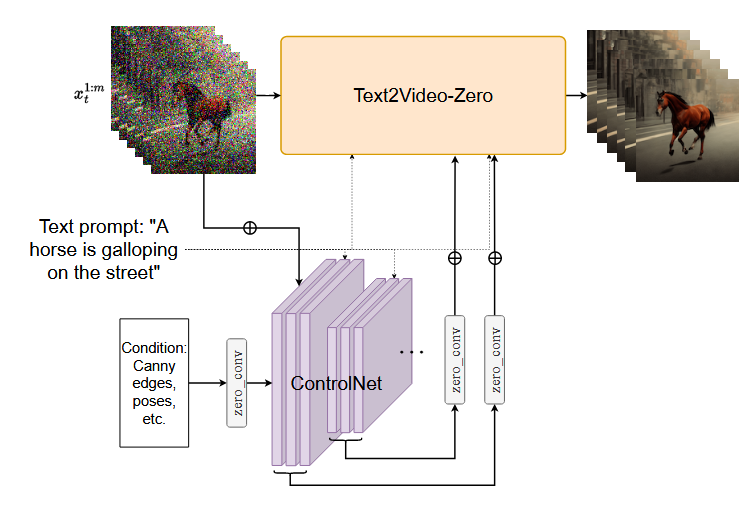
拓展应用:与ControlNet结合
ControlNet允许在生成过程中使用边缘、姿态、语义掩码、图像深度等作为条件进行控制。
- 在视频潜变量中融入运动信息,将UNet中的自注意力模块换成帧间注意力模块。
- ControlNet 会创建一个可训练的 UNet 编码器副本(包括中间块),用于学习额外的条件控制,将每一层的输出添加到原始 UNet 的跳跃连接中。
本博客所有文章除特别声明外,均采用 CC BY-NC-SA 4.0 许可协议。转载请注明来源 由本自性清净故,令诸爱染悉无垢!
