LAMP
LAMP: Learn A Motion Pattern for Few-Shot-Based Video Generation阅读笔记
motivation
如何更好的平衡微调T2I模型以达到T2V中的生成自由度和时间连贯度:
- 由于训练数据过小,易造成过拟合,伤害生成自由度。
- T2I扩散模型的主要针对空间维度的操作,从视频中提取活动信息的能力可能不足。
整体架构:
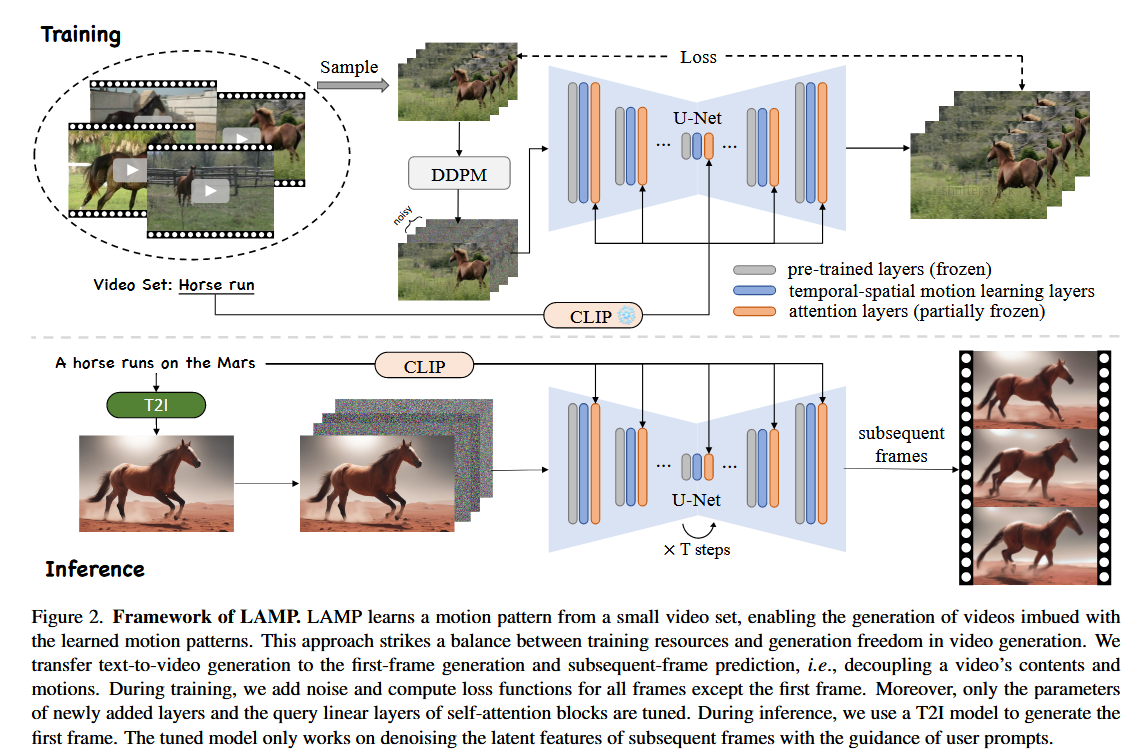
创新点1:首帧约束的生成过程
将视频
编码为潜变量序列 。 在训练时保留第一帧潜变量
,并对所有后续帧 加噪,则训练的损失函数可改写成:
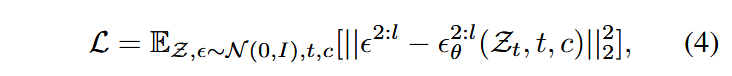
其中,
- 推理时,使用SD-XL生成第一帧图像
,将其解码为 。 - 将序列
送入模型中,始终保持第一帧潜变量不变并对后续帧去噪,其中 是随机噪声。
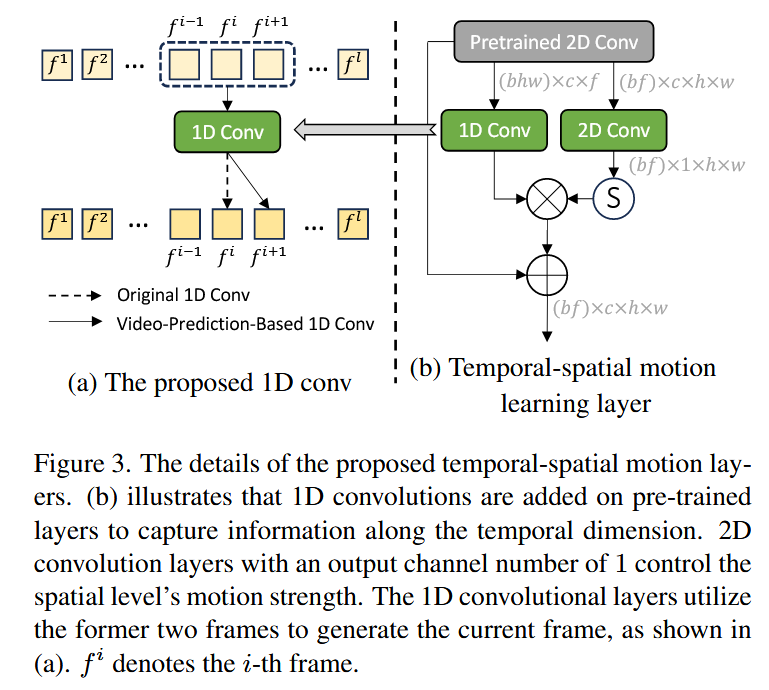
创新点2:从T2I到T2V的适应性改进
时空联合的运动学习层
- 原始潜变量形状为
。 - 在时间分支上,将原始潜变量变形为
送入1D卷积层,并预测 。 - 在空间分支上,将原始潜变量变形为
送入2D卷积层,后接Sigmoid函数,提取空间信息。
注意力机制更改
- 仿照Text2video-zero将自注意层的Key、Value换成第一帧的相关信息。
- 仿照Tune-a-video引入时间注意力层。
创新点3:共享噪声采样策略(推理过程)
- 首先采样共享噪声
,再分别对除第一帧外的所有帧从相同分布中采样噪声 - 混合基础噪声和每帧的独立噪声:
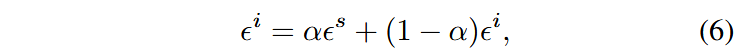
这种方法确保每一帧的噪声水平保持一致,最终体现为生成视频的时间一致性。降低噪声方差可以收缩潜空间的动态范围,从而提升生成过程的稳定性。
其它
此外在潜空间中引入了AdaIN技术,并在像素空间中采用直方图匹配方法。
本博客所有文章除特别声明外,均采用 CC BY-NC-SA 4.0 许可协议。转载请注明来源 由本自性清净故,令诸爱染悉无垢!
