GPT4Motion
GPT4Motion: Scripting Physical Motions in Text-to-Video Generation via Blender-Oriented GPT Planning阅读笔记
motivation
- 受这些 LLM 辅助方法的启发,本文提出了一种新的视角来解决运动不连贯问题。
- 提出了一个利用 GPT-4 的战略规划能力、Blender 的物理模拟能力以及 Stable Diffusion 的卓越图像生成能力的无需训练的视频合成框架。
- 主要针对刚性物体、布料、液体进行模拟。
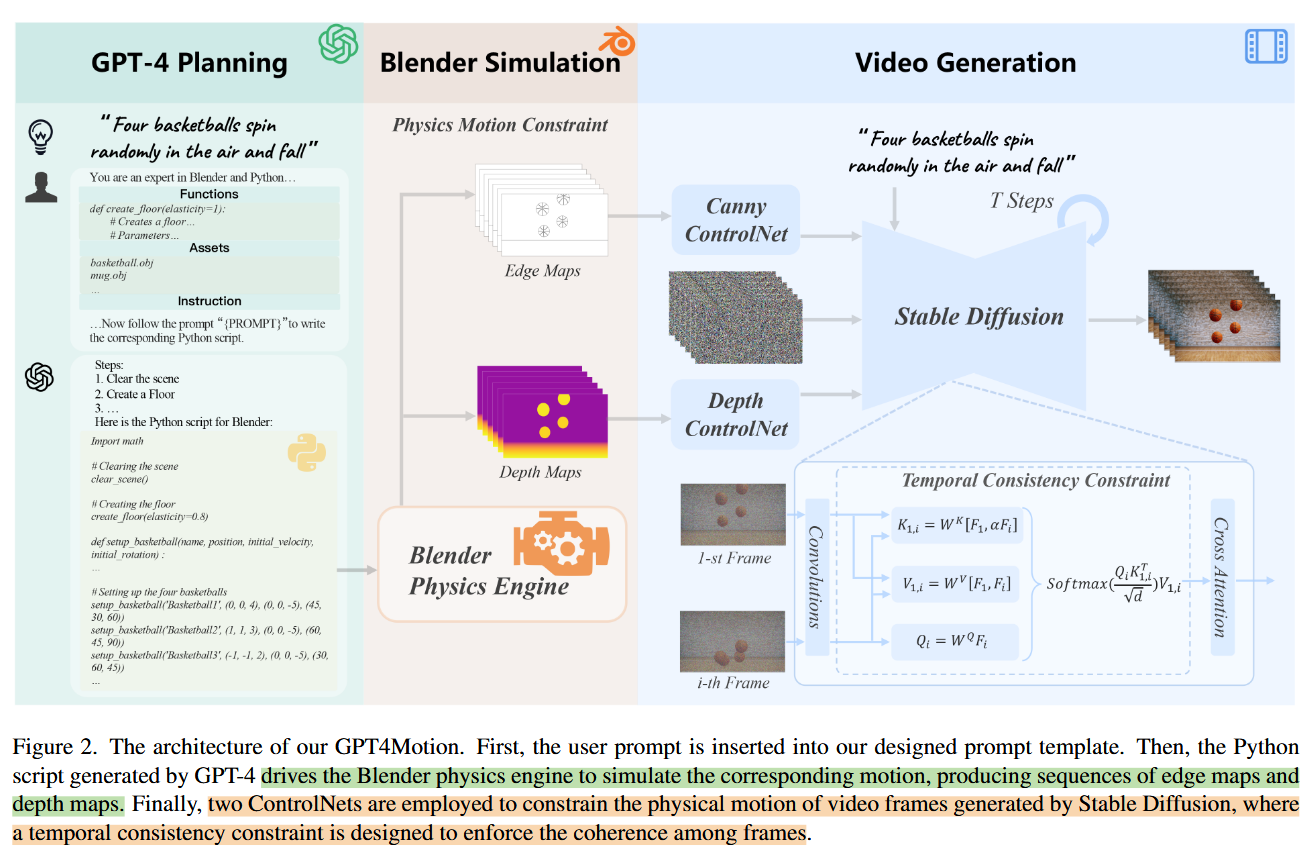
阶段一:利用GPT4使用Blender物理模拟
- 针对GPT-4直接在Blender中创建 3D 模型困难的问题,作者收集了日常生活中的常见3D物体模型,并可以通过脚本根据文本提示自动加载 3D 模型。
- 指导GPT-4对一些完成场景初始化与渲染功能、对象创建与导入功能、物理效果功能的函数进行封装。
- 在自主设计的通用提示模板嵌入封装的 Blender 函数、外部资源和指令,直接引导 GPT-4 生成相应的 Blender Python 脚本。Blender 使用该脚本生成边缘图和深度图序列。
阶段二:视频生成
- 利用了文生图模型Stable Diffusion XL(SDXL)
- 由于ControlNet只能基于一种约束生成图,分别使用基于Canny边缘的 ControlNet 和基于深度图的 ControlNet,既利用边缘图反映纹理变化,还利用深度图形成更准确的3D布景。
具体实现上,直接将两个ControlNet的中间结果相加作为SDXL生成的约束条件。
为了增强视频的时间连续性,将SDXL的自注意力层改为跨真注意力,即对于帧
,跨帧注意力表示为:
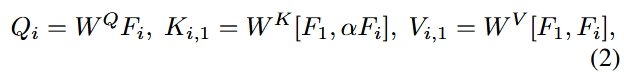
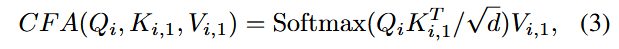
其中的超参数
本博客所有文章除特别声明外,均采用 CC BY-NC-SA 4.0 许可协议。转载请注明来源 由本自性清净故,令诸爱染悉无垢!
