MoVideo
MoVideo: Motion-Aware Video Generation with Diffusion Model阅读笔记
整体架构
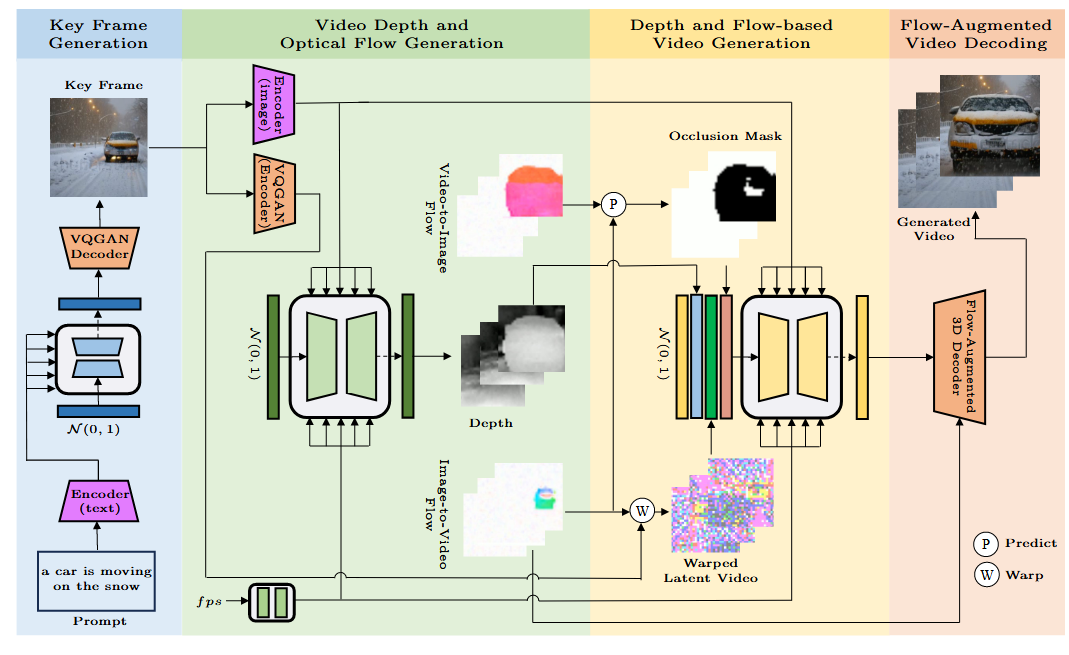
- 首先根据文本生成关键帧(利用现有T2I模型);再从关键帧中生成视频的深度和光流;根据关键帧、光流、深度生成视频潜变量;利用基于流增强和特征细化的解码器解码视频。
- 从视频深度和光流两方面感知运动。深度信息用于指导每一帧的空间布局,并通过一系列深度图来捕捉视频中的运动变化;光流用于表示视频中不同帧之间的对应关系,可用于帧对齐,从而保留细节并增强时间一致性。
阶段2:深度与光流生成
- 将关键帧
送入使用文本-图像双编码器的模型 ,提取最后一个池化层前的图像嵌入 。之所以在池化层前提取是因为池化可能会破坏图像语义、空间布局和局部细节。 - 利用该嵌入与每秒帧数(fps)共同利用扩散模型生成视频深度
,图像到视频的光流 ,视频到图像的光流 。
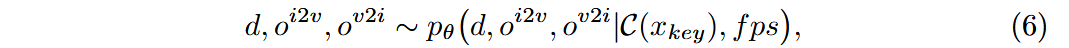
在生成光流时,本文生成的是从关键帧到其他帧的光流.
- 可以从关键帧通过光流直接获得其它所有帧,避免光流变形误差的积累。
- 可以一次对所有光流进行正则化。
在2D空间卷积/注意力模块后加入1D的时间卷积/注意力模块。
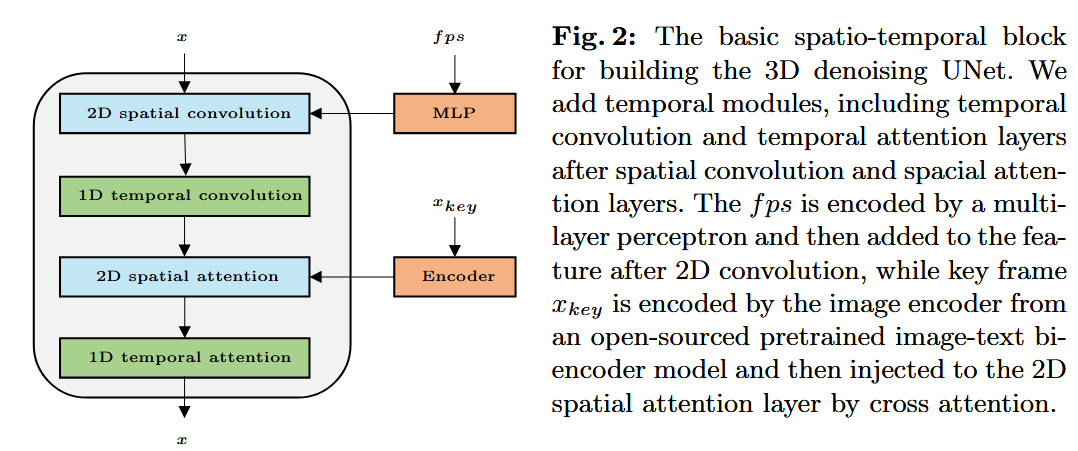
- 将深度和光流归一化到
间:
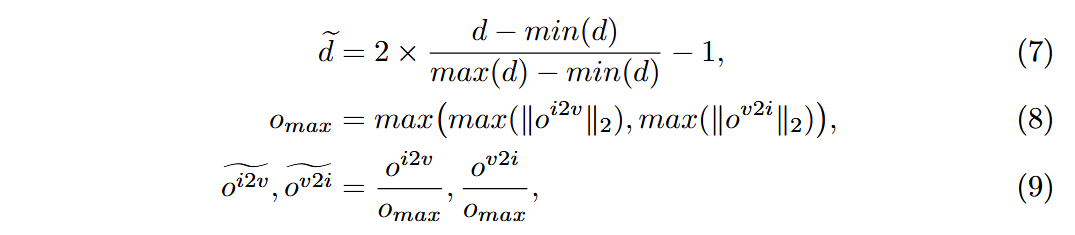
- 归一化后,为获得原始光流值进行变形,通过基于优化的方法从归一化后的深度和光流中推测原始光流最大值:
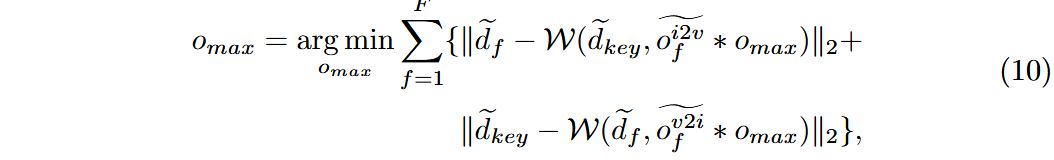
阶段3:基于深度和光流的视频生成
- 首先利用预训练的隐变量编码器将关键帧
编码为 。 - 利用隐变量计算遮挡掩码和变形的视频潜变量,其中
是非遮挡区域的阈值:
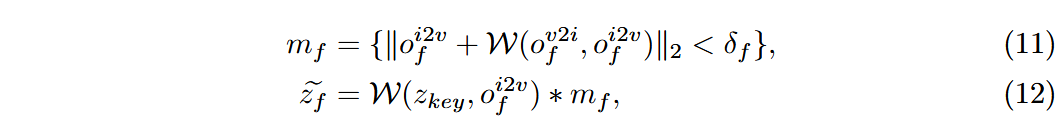
- 再次用扩散模型预测视频潜变量:
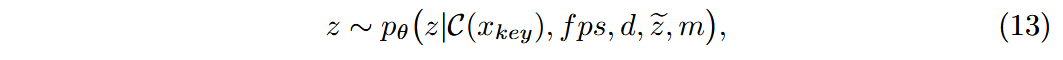
- 将视频深度 d、变形视频潜变量
和遮挡掩码 m 与 z 连接起来,输入UNet。直接拼接 时,由于其中一些错误的运动会影响视频生成,因此以0.5的概率将 替换为全0。
阶段4:光流增强的视频解码
将原先的2D解码器层扩展成3D:
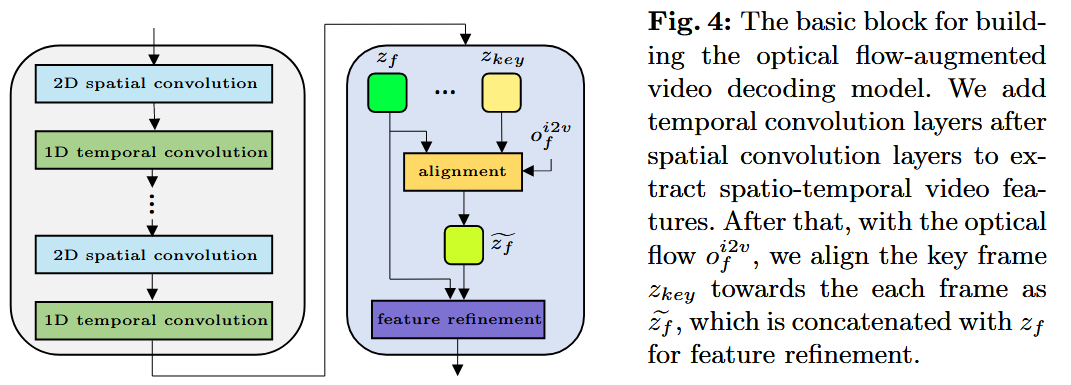
通过光流引导的可变形卷积显式对齐关键帧特征
与每一帧的特征 ,以融合跨帧信息
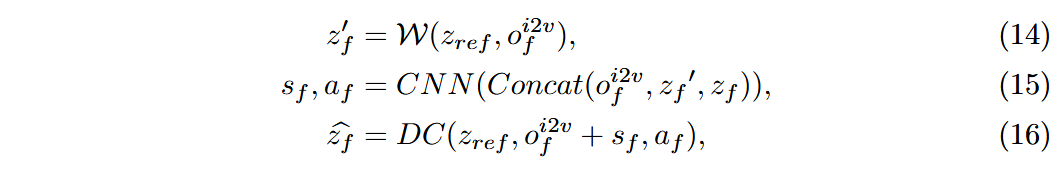
- 将对其后的特征
和原特征 融合,有:
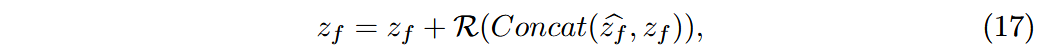
- 记解码后的视频为
,原始视频为 ,则解码器训练损失可表示为:
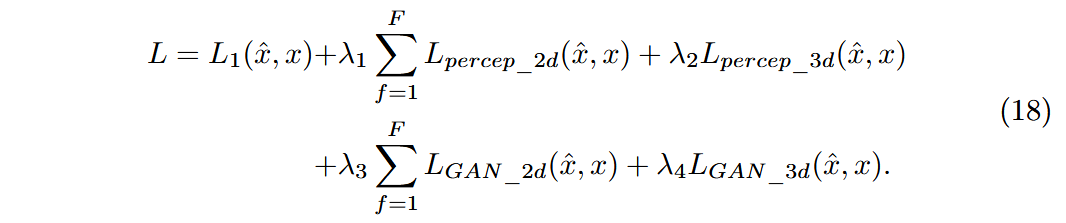
本博客所有文章除特别声明外,均采用 CC BY-NC-SA 4.0 许可协议。转载请注明来源 由本自性清净故,令诸爱染悉无垢!
