ED-VDM
Decouple Content and Motion for Conditional Image-to-Video Generation阅读笔记
motivation
- 将目标的RGB视频解耦为空间内容和时间运动两个模块,来应对运动一致性和视觉连续性的问题。
- 使用CodeC提取运动向量和残差,对视频进行压缩,减少存储或传输视频所需的数据量。
简单版:解耦空间与时间表示
- 是保留第一帧,然后计算它与后续帧的差值,记RGB像素空间
中的视频表示为 ,其中 为帧数,即:
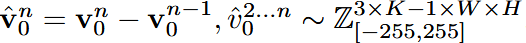
- 为了像差值中注入第一帧的内容,将第一帧解码为
,并将其沿着通道维度和噪声学习目标进行拼接,训练目标,共同优化解码器 和噪声预测器
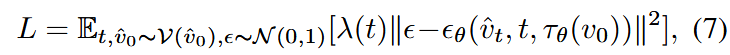
高效改进
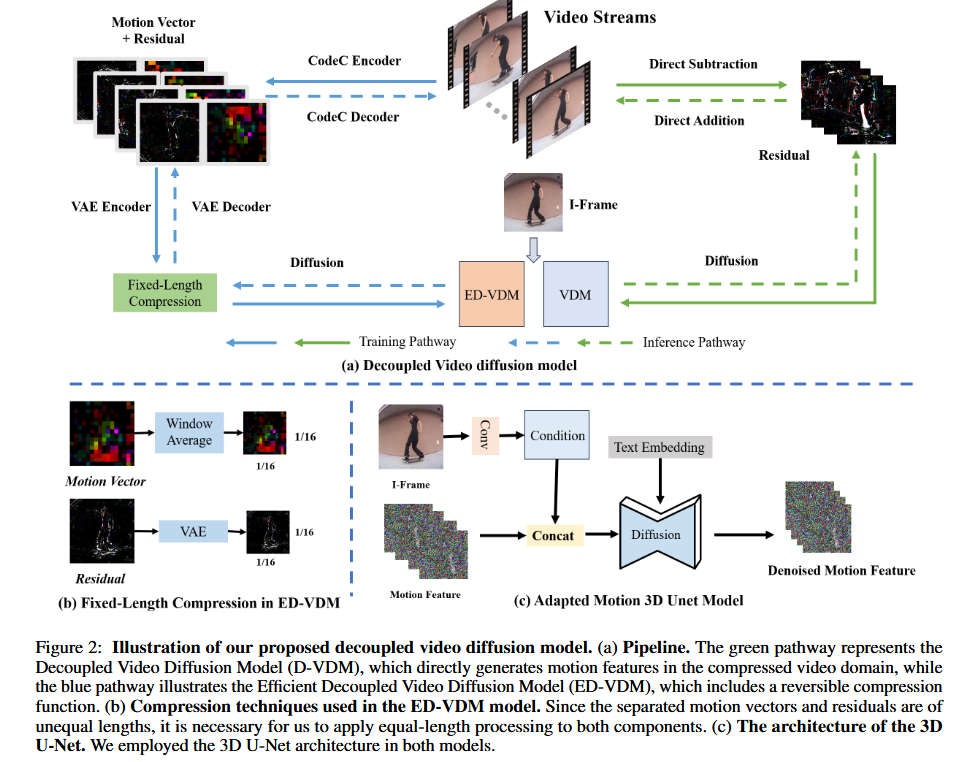
- 仿照H.264的范式,将视频分为I-frame(含有全部图片信息的独立帧)和P-frame(通过运动向量和残差编码图像差异的预测帧),使用可逆变换
获得运动向量 和残差 ,即$f(v)= - 记
为当前帧, 为上一帧,将 分成若干个不重叠的 像素块,记为 。 - 对每个块
中最小化绝对损失寻找其在当前帧中的相应块,进而获取运动向量 :
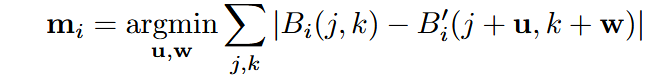
- 则相应残差可定义为
,接着利用 生成P-frame。 - 运动向量大小是原始图像的
,残差大小与原图像相同。 - 使用潜变量扩散模型的自编码器Latent Diffusion autoencoder对其进行压缩,并使用
损失对其进行训练。
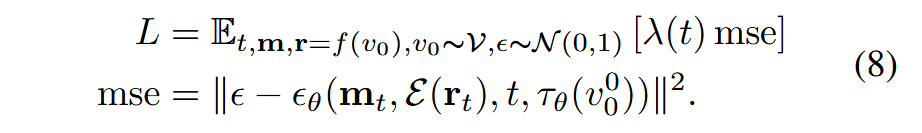
整体框架对比:
本博客所有文章除特别声明外,均采用 CC BY-NC-SA 4.0 许可协议。转载请注明来源 由本自性清净故,令诸爱染悉无垢!
