CLIPSeg
Unveiling the Knowledge of CLIP for Training-Free Open-Vocabulary Semantic Segmentation阅读笔记
总览
语义分割时,视觉编码器的输出
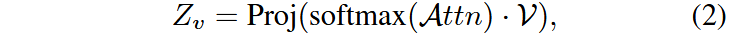
当前面对两大问题:一是模型深层的注意力会关注到一些无关的信息,二是深层的
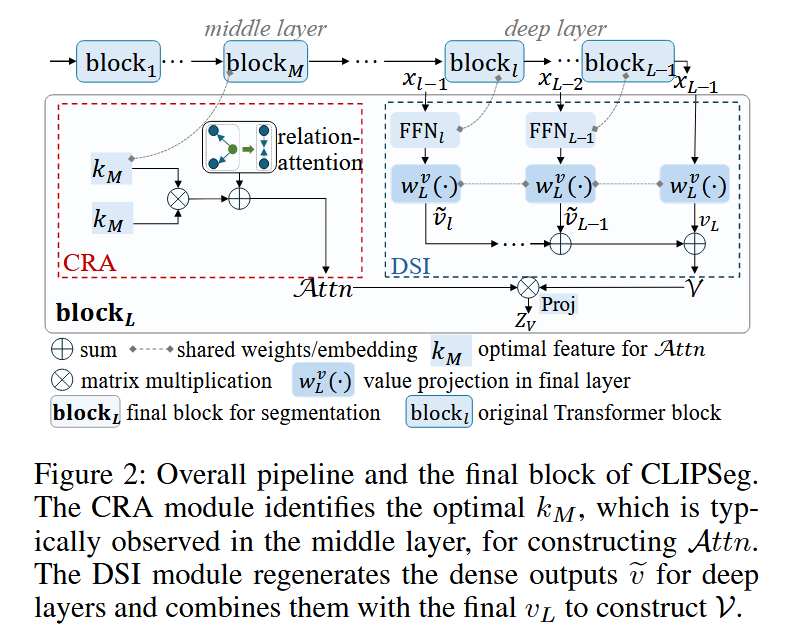
模块一:Coherence Enhanced Residual Attention(CRA)
拼接单层多头注意力模块的所有输出,形成该层的
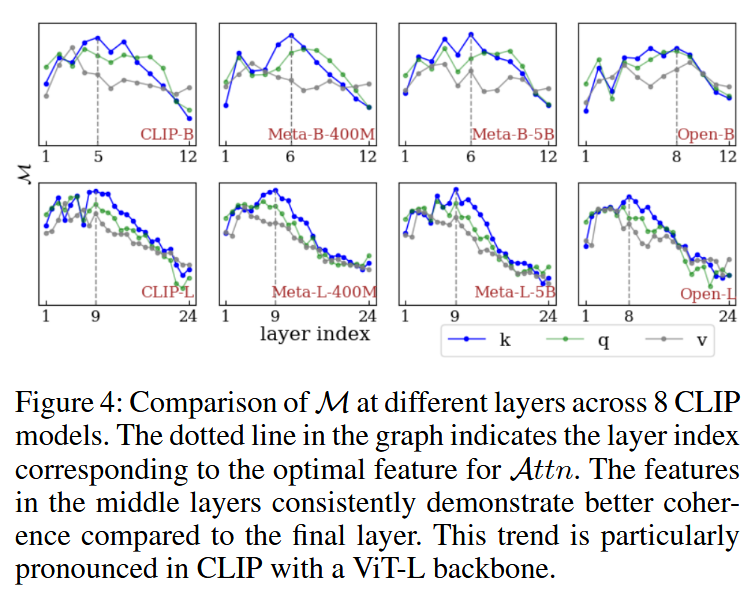
可以发现,在较为中间的层,类间连贯性判断是最准的。传统方法使用self-self attention (SSA)来减少对于不相干区域的关注,但这种方法只考虑到了两个patch间的关系,没考虑到它们和其它patch间的关系,因此提出CRA,记
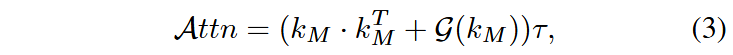
模块二:Deep Semantic Integration(DSI)
本文认为最后一层的
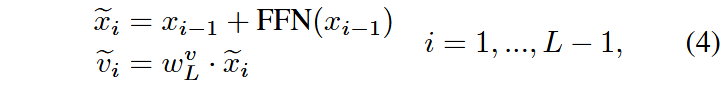
定义逐像素的平均预测准确率为跨模态语义对齐分数
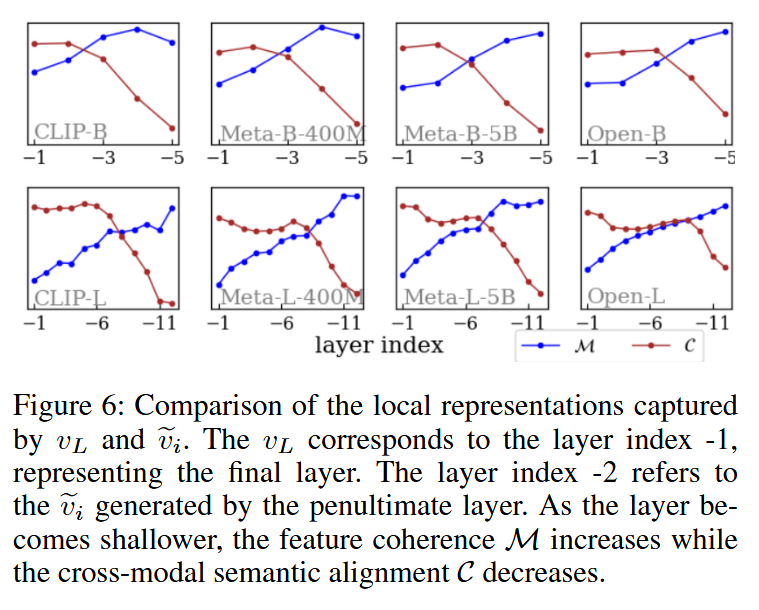
可发现层越深跨模态语义越对齐,类间连贯性越低。为了平衡两种能力,将不同层的
本博客所有文章除特别声明外,均采用 CC BY-NC-SA 4.0 许可协议。转载请注明来源 由本自性清净故,令诸爱染悉无垢!
