ProPETL
Progressive Parameter Efficient Transfer Learning for Semantic Segmentation阅读笔记
总览
从分类到语义分割的迁移学习需要改变大量参数,现有迁移学习方法表现不佳。为此引入带中间任务的渐进式学习方法,将迁移过程分为两个阶段:中游适应阶段和下游微调阶段,首次在COCO-Stuff10k上效果超过全量微调。
渐进式迁移学习方法选择
备选方案1:Generalized Parametric Adaptation(GPA)
在FFN层中引入bottleneck结构随机初始化的adaption module,使得前向传播过程变为:
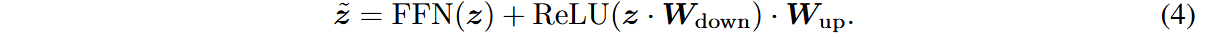
中游适应阶段时,冻结原始权重参数
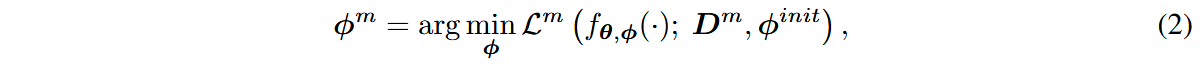
下游微调时,优化目标变为:
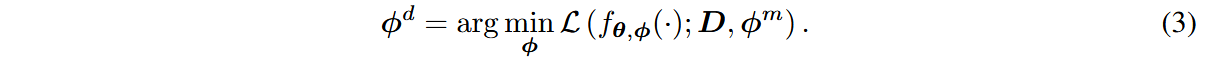
备选方案2:Decoupled Structured Adaptation(DSA)
同样在FFN层中引入bottleneck结构随机初始化的adaption module,但将其参数分为
中游适应阶段时,前向传播过程为:
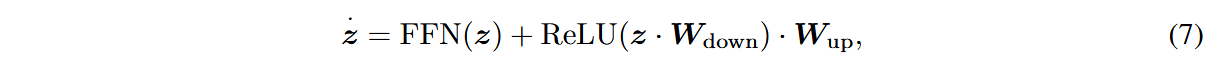
冻结原始权重,只优化
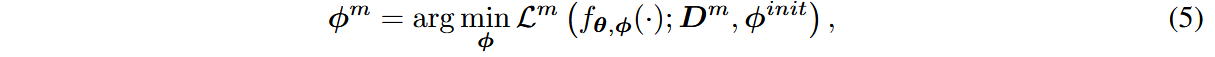
下游微调阶段,将原始前向传播的激活与中游适应后的激活拼接起来,前向传播过程变为:
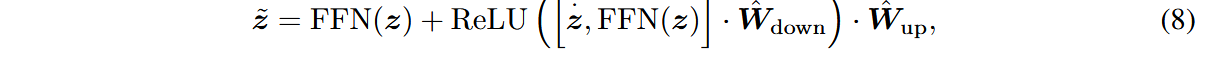
冻结
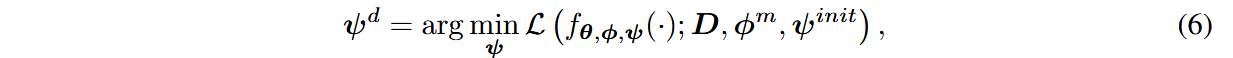
两方案对比图
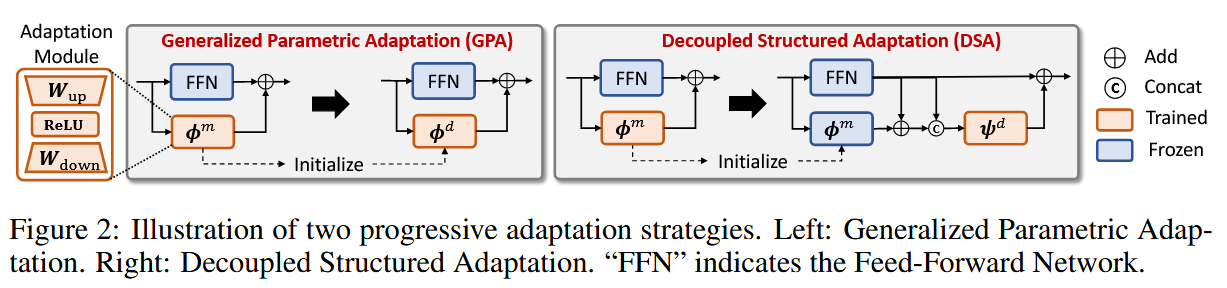
经实验验证,DSA表现持续优于GPA,因此最终ProPETL框架选择使用DSA方法。
中游任务设计
角度1:感知粒度迁移(Perception Granularity)
记下游任务数据集为
当以整幅图片为感知粒度时,池化窗口大小为
当以一个patch为感知粒度时,池化窗口与patch大小一致为
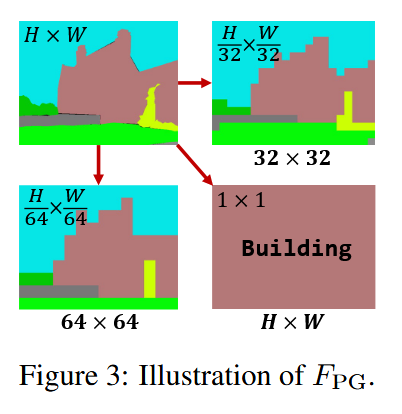
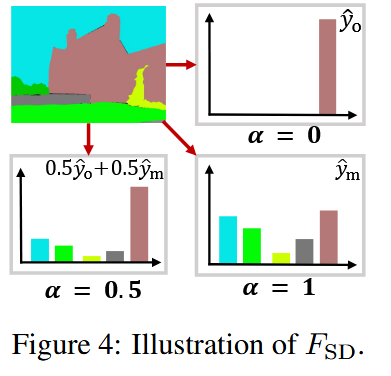
角度2:监督多样性迁移(Supervision Diversity)
在
整体框架
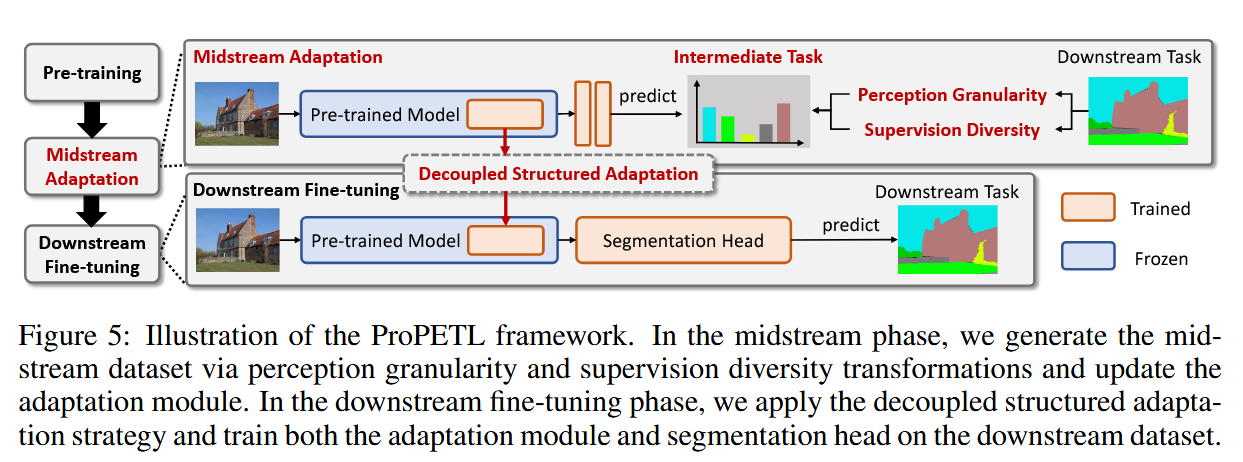
实验结果现实DSA持续优于GPA,作者认为这是因为在下游微调时,GPA会遗忘中游适应时学习到的知识。
本实验在中游任务设计时选取池化窗口大小为
本博客所有文章除特别声明外,均采用 CC BY-NC-SA 4.0 许可协议。转载请注明来源 由本自性清净故,令诸爱染悉无垢!
