KnowledgeBridger
Knowledge Bridger: Towards Training-Free Missing Modality Completion阅读笔记
motivation
现有的模态缺失信息补全方法(Missing modality completion、MMC)依赖于大量的训练数据,且泛化效果不佳,面对OOD数据表现较差。
本方法是第一个在MMC领域使用多模态大模型的方法,总体分三步走,先使用LMM提取关键信息生成知识图,再驱使LMM生成候选缺失信息,最后对各候选进行评分,输出分数最高项。
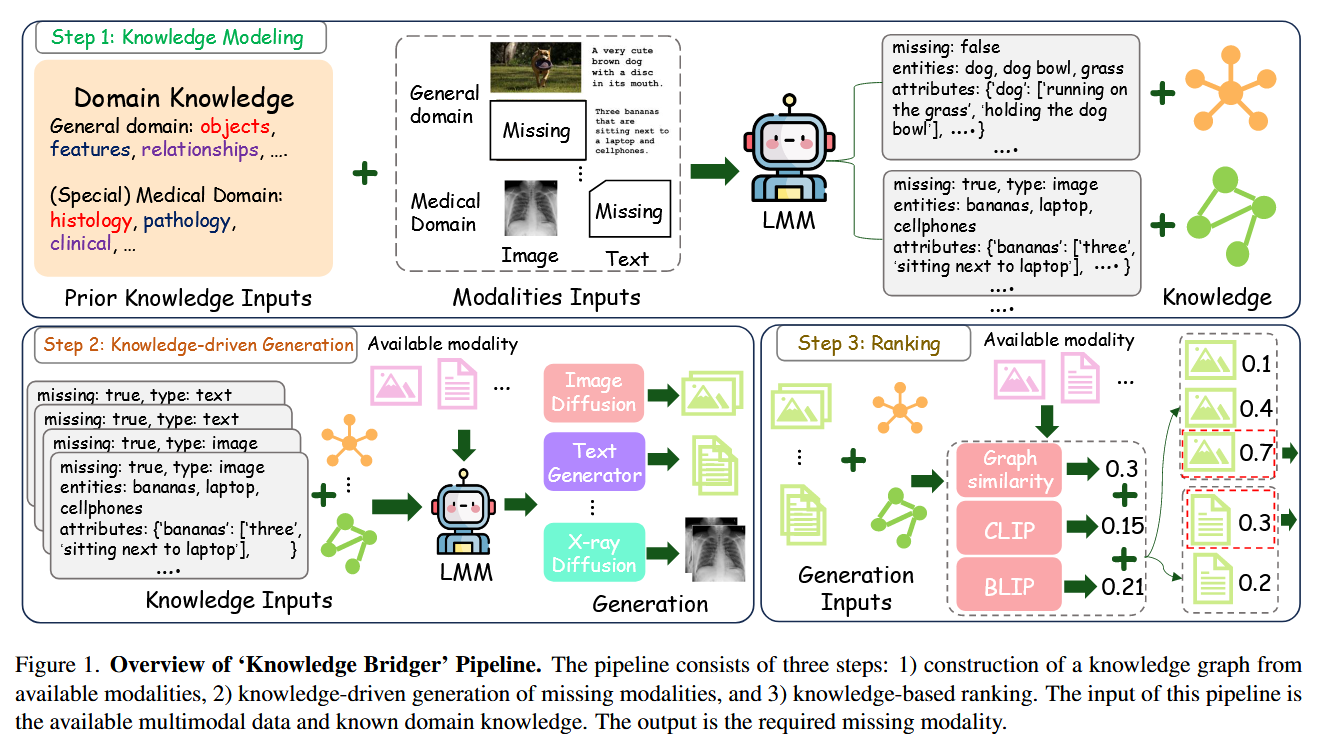
步骤一:知识图建模
使用LMM通过CoT方法抽取可用模态信息中的实体、关系、特性等关键元素:首先驱使LMM对每个提取规则生成一段较为精简回复,再从回复中抽取相应的实体关系对。
对于部分较为专业的领域使用上下文学习方法注入相关先验知识。
步骤二:生成候选缺失信息
对于缺失的信息对应的实体O,遍历知识图中所有与实体O相邻的元素,让LMM以每个元素作为主体,同时涵盖知识图谱中的所有节点和属性生成缺失信息的文字描述。并将这些文字描述根据缺失信息的类别传入diffusion model/LMM。
对于图像类的缺失信息使用diffusion model生成,对于文字类的确实信息使用LMM生成。
步骤三:对候选缺失信息排序
首先对知识结构相似性计算分数,记
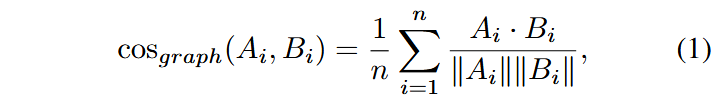
接下来要对不同模态间的语义连贯程度计算分数,仍然采用余弦距离
记
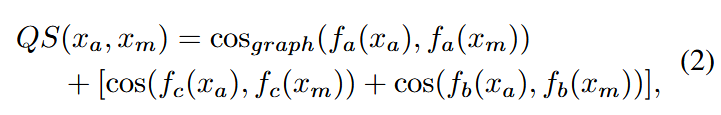
分数越高代表生成的候选确实信息越可靠,最终输出分数最高的候选缺失信息。
其它
所有实验只用了4张24G的4090
本博客所有文章除特别声明外,均采用 CC BY-NC-SA 4.0 许可协议。转载请注明来源 由本自性清净故,令诸爱染悉无垢!
