LogSAD
Towards Training-free Anomaly Detection with Vision and Language Foundation Models阅读笔记
motivation
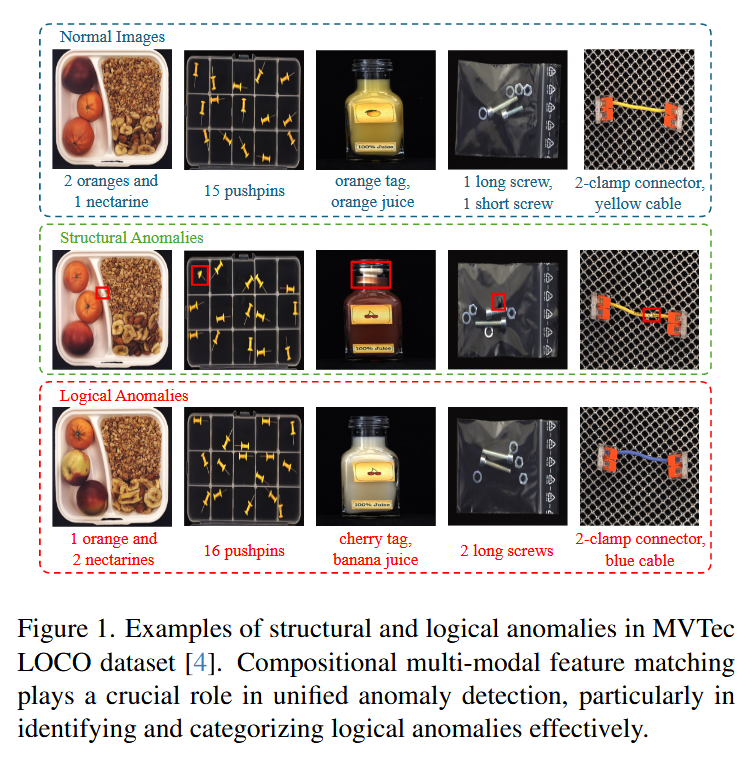
现有的大多异常检测方法着重于结构异常(structural anomaly)的检查而忽略了逻辑异常(logical anomaly),为此提出了一个可以同时检查两种异常的框架。
模块一:Match-of-thought(MoT)
收到思维链(CoT)方法的启发,MoT分多步完成prompt and match engineering。
首先使用GPT-4V生成无异常图像的文字说明和匹配提案,接下来总结文本提示的interests并制定了相应的异常检测需要检查的规则。

模块二:多粒度异常检测器
Patch-level
使用CLIP和DINOv2提取不同层级的patch feature,记
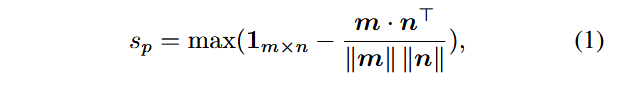
interest-level
使用CLIP和SAM,根据MoT中获得的interests,提取相应的featue并通过平均池化聚合。记
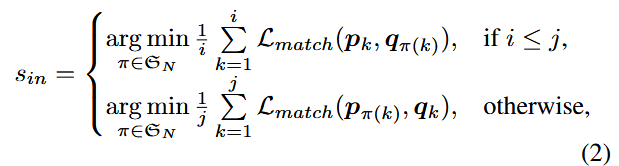
其中:
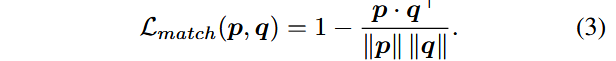
composition-level
使用CLIP提取图像目标
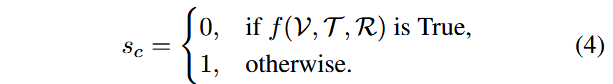
其中
最终分数的归一化融合
首先使用无异常图像集计算patch-level异常分数的均值和方差
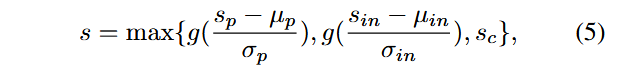
其中$g(·)是Sigmoid函数。
整体过程

本博客所有文章除特别声明外,均采用 CC BY-NC-SA 4.0 许可协议。转载请注明来源 由本自性清净故,令诸爱染悉无垢!
