SliceGPT
SliceGPT: Compress Large Language Models by Deleting Rows and Columns阅读笔记
Transformer架构的计算不变性
传统Tranformer架构为:
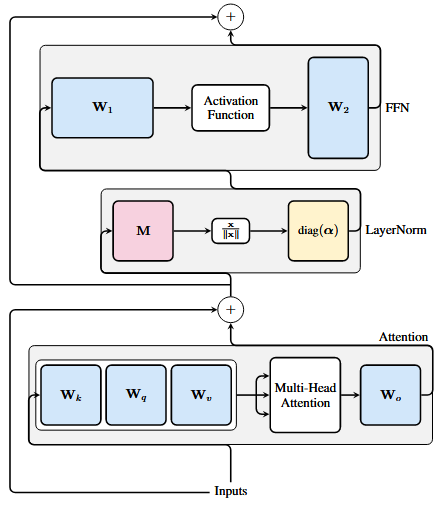
注意力模块QKV的分别投影可以看作拼接为

对于RMSNorm,在归一化前乘正交矩阵
即:
可通过如下矩阵变换将所有
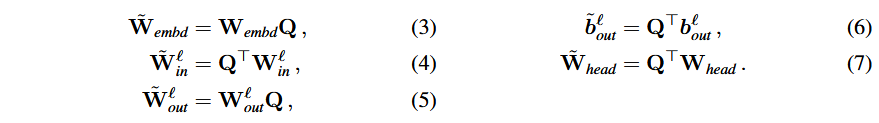
LayerNorm变RMSNorm
LayerNorm到RMS的数学关系可看作:
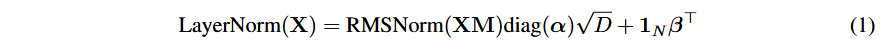
其中
将
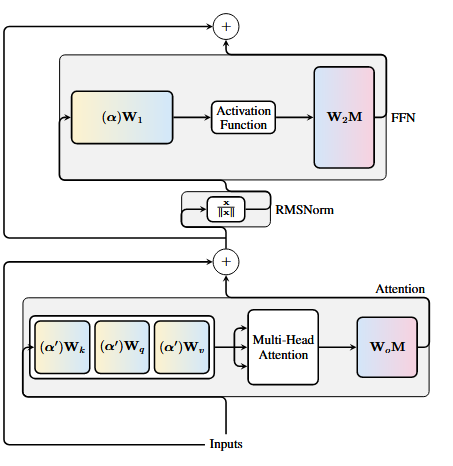
不同块采用不同的旋转矩阵
因为不同层的激活不同,其使用的旋转矩阵也不应相同。旋转矩阵的计算使用PCA方法,记第
为了保持计算不变性,对于残差分支也要施以
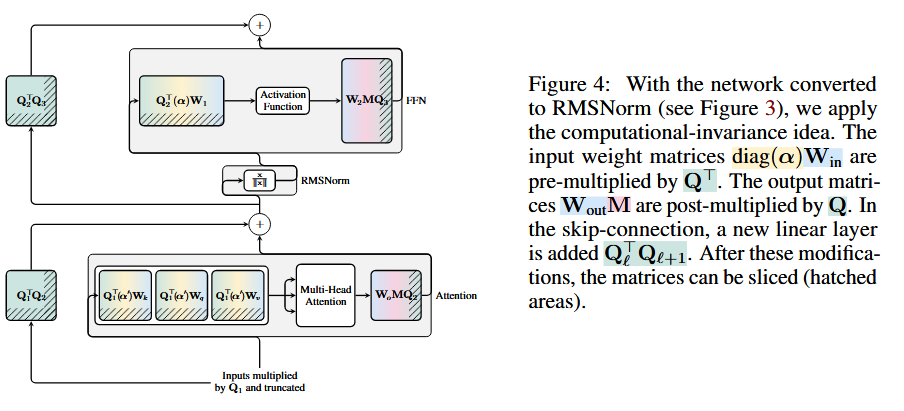
核心:权重裁剪
使用低维度矩阵Z代替原本的激活达到裁剪权重矩阵的目的,其中
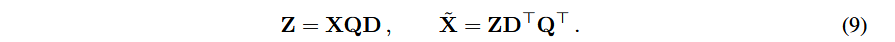
其它
KurTail就是延续了这里的计算不变性(computational invariance)框架。
本博客所有文章除特别声明外,均采用 CC BY-NC-SA 4.0 许可协议。转载请注明来源 由本自性清净故,令诸爱染悉无垢!
