PD-Quant
PD-Quant: Post-Training Quantization based on Prediction Difference Metric阅读笔记
motivation
- 现有方法往往尝试输入输出间的距离,只利用了局部信息没有理由全局信息。
- 校准集较小已发生过拟合。
创新点1:预测差异损失(PD Loss)
假定激活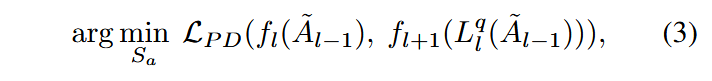
其中
该损失和真正的任务损失(CE)表现更一致,如下图,实际的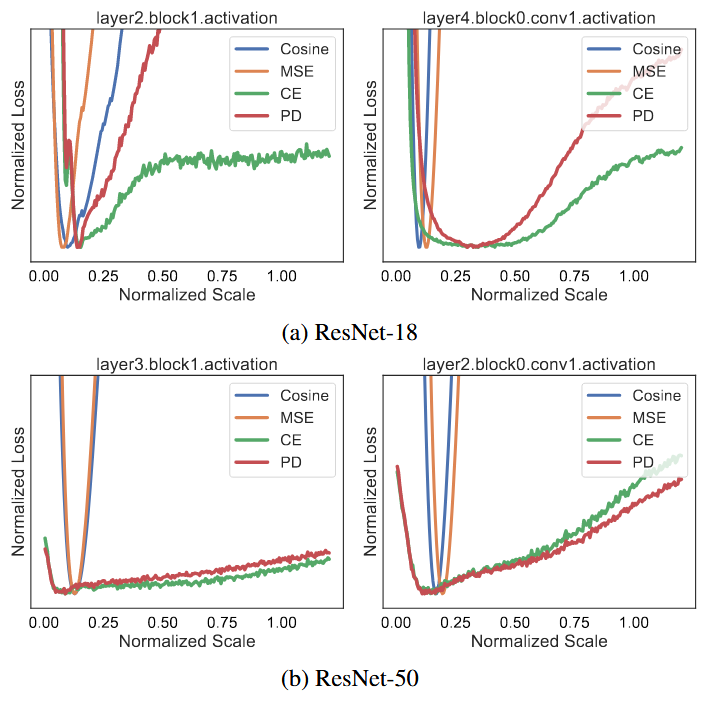
为了避免过拟合,在损失中加入正则项: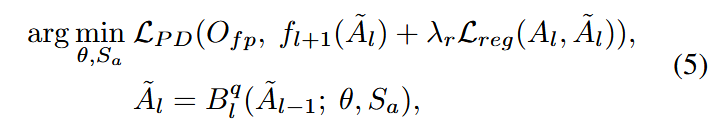
其中
创新点2:依据Norm进行分布校正
为进一步防止对校准集过拟合,根据Norm层的均值和方差对各层输入进行微调,目标损失函数: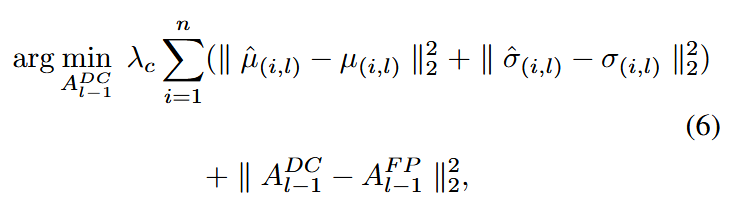
其中
OAD为原始激活,ADC为校正后,校正后的效果:
其它
PD Loss搜索只针对激活,权重未采用。
本博客所有文章除特别声明外,均采用 CC BY-NC-SA 4.0 许可协议。转载请注明来源 由本自性清净故,令诸爱染悉无垢!
