BitStack
BitStack: Any-Size Compression of Large Language Models in Variable Memory Environments阅读笔记
motivation
现有方法不能动态调整被压缩模型大小,且现有权重分解方法和量化方法间精度尚有差异。
创新点1:迭代式绝对值分解
将矩阵符号值分离,改写为
对原始矩阵进行权重分解则变为:
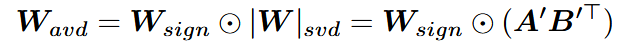
其残差可记作:
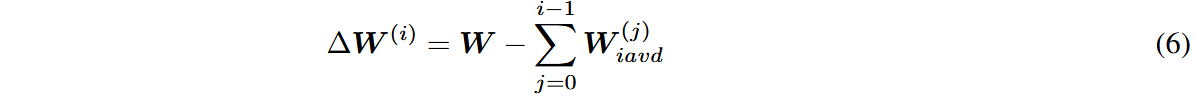
对残差进行二次分解:
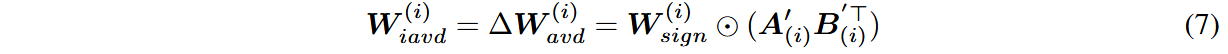
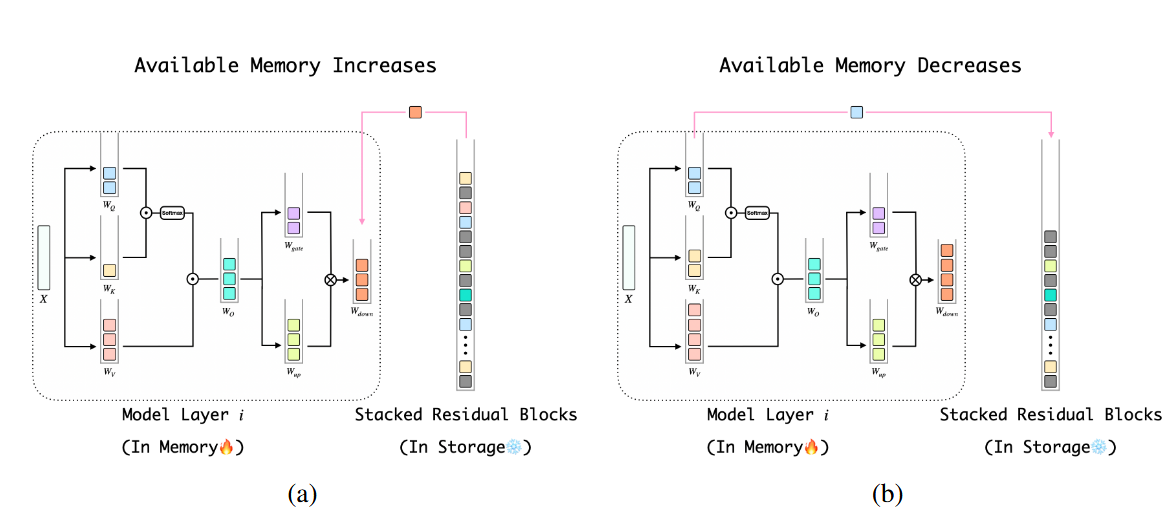
总的权重分解估计公式则为,可以根据可用内存量动态决定load多少块:
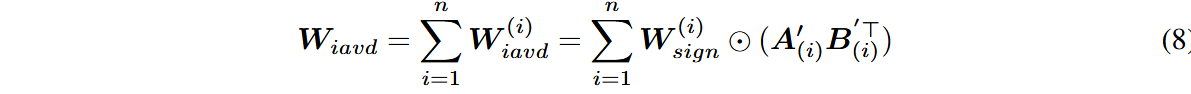
创新点2:动态加载排序
由创新点1显然第
将模型的前
更重要的块在内存增加时会更优先被load
其它
为了应对激活中的绝对值采用了AWQ中逐通道缩放的方法,缩放因子直接通过该通道激活的二阶范数计算,即
本博客所有文章除特别声明外,均采用 CC BY-NC-SA 4.0 许可协议。转载请注明来源 由本自性清净故,令诸爱染悉无垢!
