ASVD
ASVD: Activation-aware Singular Value Decomposition for Compressing Large Language Models阅读笔记
motivation
大语言模型激活中的激活不均匀为低秩分解带来了挑战,不同层关于低秩分解的敏感度不同,应有不同的处理方法。
创新点1:激活感知的SVD矩阵分解
即使权重矩阵的压缩损失
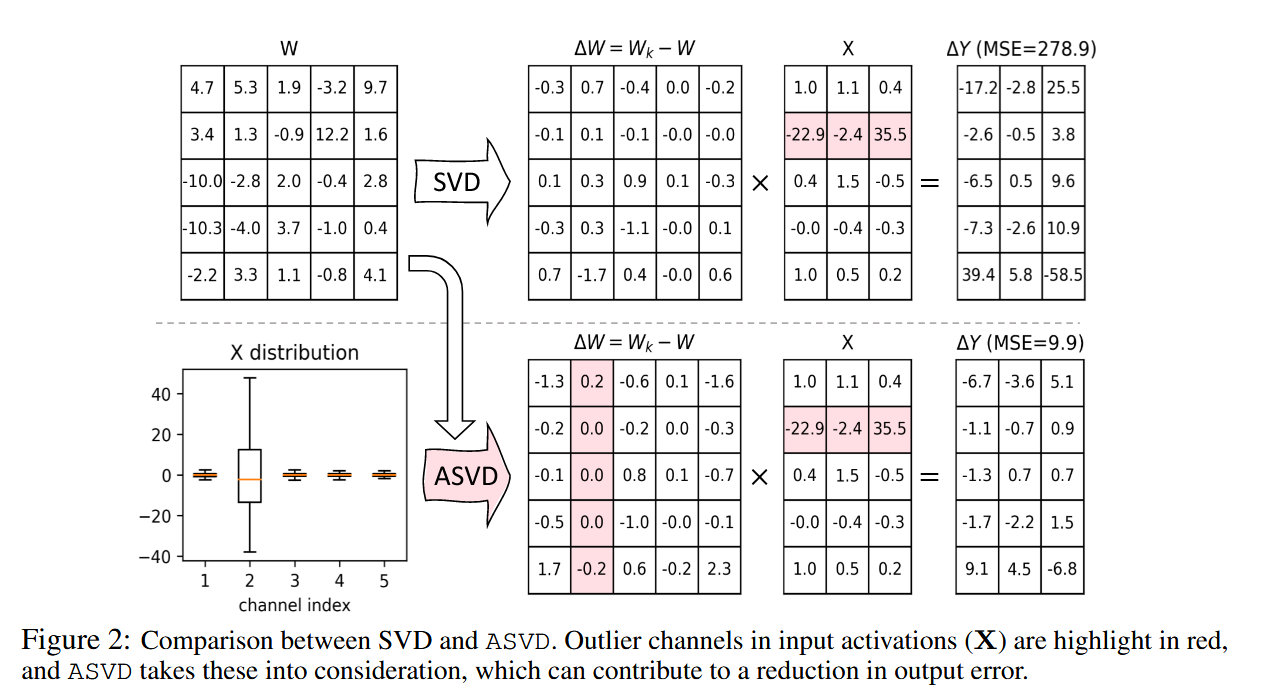
为此,本方法将压缩目标转换为最小化输出的差距:
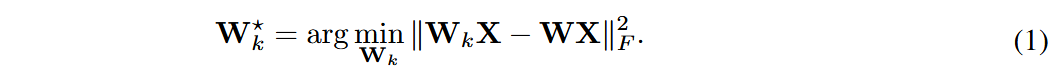
通过变换矩阵S平衡权重与激活的关系(个人觉得直观的来说,对于均值更大的激活channel,其对应的权重在低秩分解时应该更关注一点),使得前向传播变成
这里的S有两种计算方式,第一种是直接对激活进行统计计算
首先对
为抵消变换矩阵S的影响取
创新点2:基于敏感度的混合分解策略
预定义一系列截断比率
敏感度的计算方法为分别对该层权重矩阵使用该比率的低秩分解矩阵替换,测量其在校准集上的困惑度提高的大小,提高的困惑度越高越敏感。
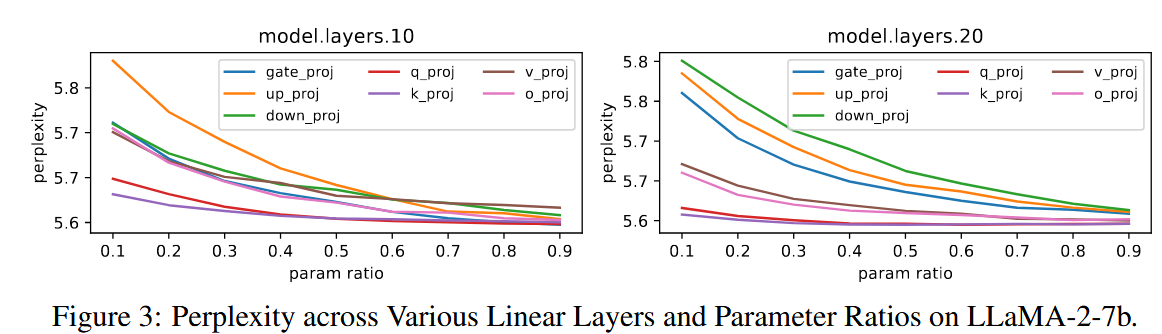
可看出保留的秩越少越敏感、MLP通常比注意力模块敏感。
假设每层间相互独立,提出两种(目标为参数量和目标为困惑度)基于二分法进行最优截断比率的寻找策略。
目标为参数量的二分法伪代码如下,主要就是按照敏感度从小到大排列,将每层的截断秩设置为敏感度高的那一半中的该层最低比率对应的秩,到达目标参数量就在敏感度低的那一半里再二分(求更高精度),否则就在敏感度高的那一半里二分(保目标参数量):

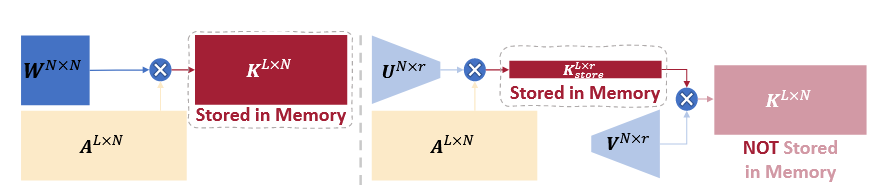
其它:关于KV Cache的压缩
在推理时,矩阵
本博客所有文章除特别声明外,均采用 CC BY-NC-SA 4.0 许可协议。转载请注明来源 由本自性清净故,令诸爱染悉无垢!
