SVD-LLM
SVD-LLM: Truncation-aware Singular Value Decomposition for Large Language Model Compression阅读笔记
motivation
当前基于奇异值分解的方法缺乏奇异值与量化损失函数之间具体的的关系证明,丢弃较小奇异值也可能导致较大的损失
SVD后没有对分解后的低秩向量微调补偿。
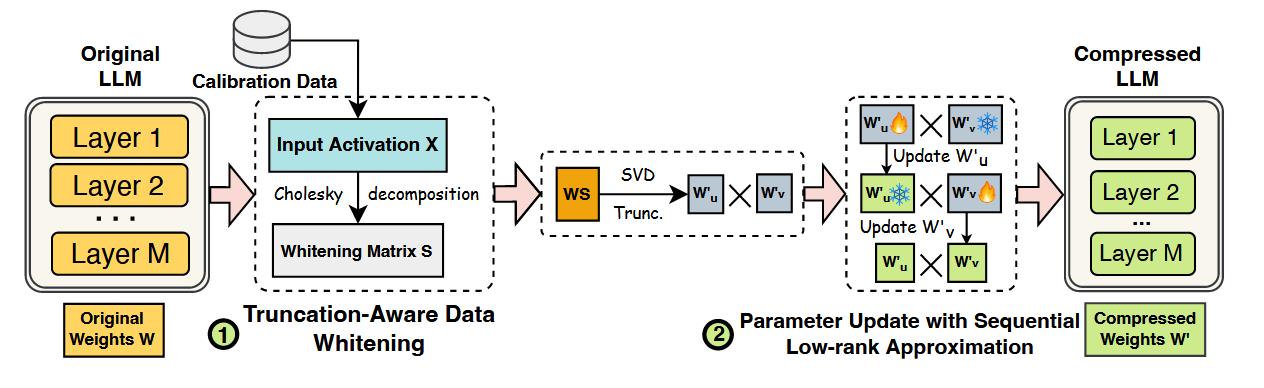
创新点1:分解前数据白化
首先收集校准数据
记将
已知矩阵 A 的 Frobenius 范数(维度为 m×n)可以推导为它的 Gram 矩阵(
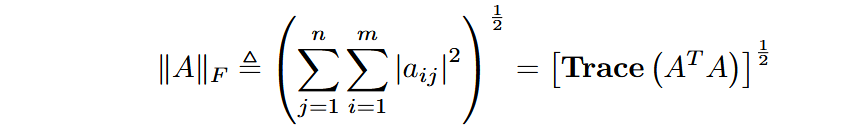
截断一个奇异值时,其量化损失可表示为:
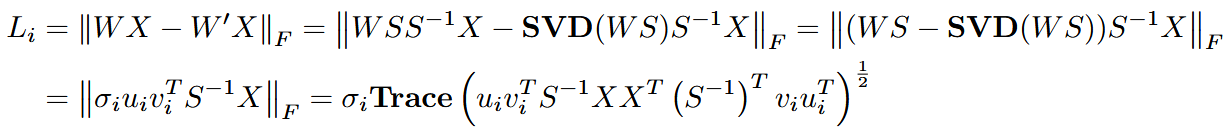
带入
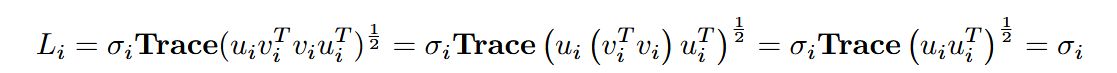
同理,截断多个奇异值时,其量化损失为奇异值平方和的平方根:
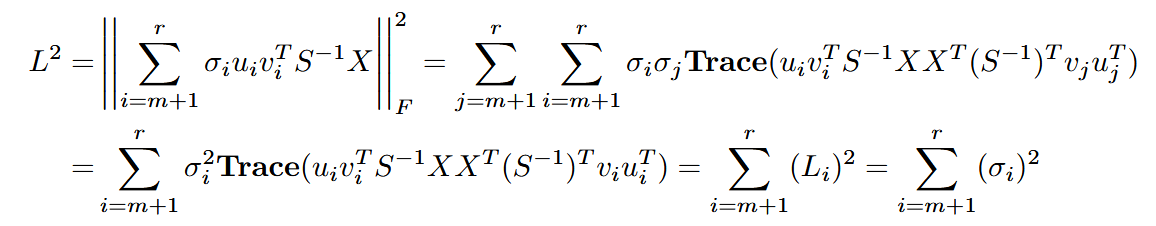
创新点2:SVD分解后LoRA补偿
将权重矩阵分解为
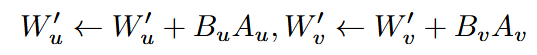
其中
其它
这个白化矩阵的应用倒是和CASP那篇基本一样,看了下时间似乎CASP晚些,但CASP主要聚焦于混合超低比特权重分解。
本博客所有文章除特别声明外,均采用 CC BY-NC-SA 4.0 许可协议。转载请注明来源 由本自性清净故,令诸爱染悉无垢!
