BoA
BoA: Attention-aware Post-training Quantization without Backpropagation阅读笔记
motivation
基于梯度的重建优化方法受参数规模限制难以迁移到大语言模型上,传统的基于变换的量化方法又欠考虑了层间关系,因此提出了一种无需BP,综合考虑QKVO层相互依赖的量化方法。
创新点1:基于QKVO层相互依赖的重建优化方法
本方法于GPTQ类似,在量化后对其余未量化权重进行更新以补偿量化损失,更新公式:
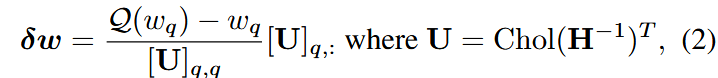
其中H是Hessian矩阵,Chol(·)代表Cholesky分解,因此U是上三角矩阵且
为了弥补GPTQ的Hessian估计方法只与输入有关,与注意力模块其他层无关的问题,本方法提出了新的Hessian估计方法:
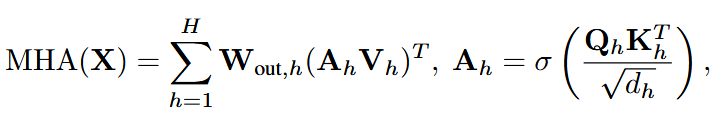
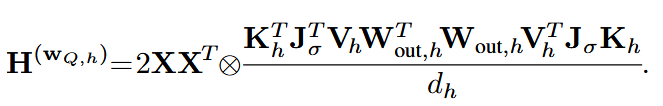
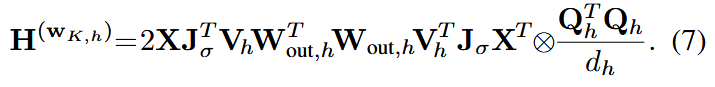
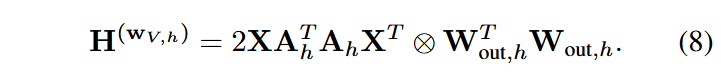
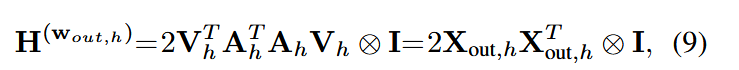
推导主要利用了

创新点2:高效实现
relaxed Hessian
为了避免计算Jacobian矩阵,将注意力模块的量化损失放宽至上界:
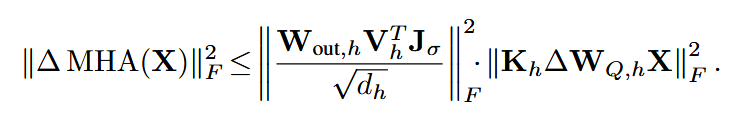
其中右侧第一项为常数,因此使用第二项替代原来的重建损失,因此可得:
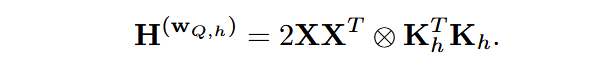
Hessian逆矩阵高效计算
利用Kronecker的属性,Cholesky分解同理:
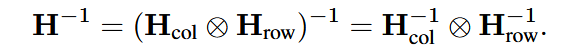
不同头间并行计算
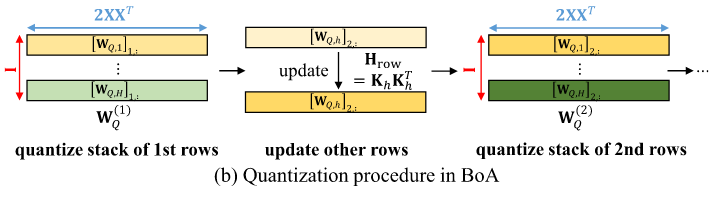
不同行间需要串行计算,为了更好地利用GPU,假设不同头间独立,将不同层间的同一行堆叠在一起进行量化(设置
本博客所有文章除特别声明外,均采用 CC BY-NC-SA 4.0 许可协议。转载请注明来源 由本自性清净故,令诸爱染悉无垢!
