AdaReTake
AdaReTaKe: Adaptive Redundancy Reduction to Perceive Longer for Video-language Understanding阅读笔记
motivation
token冗余度随时间(不同帧)和模型层数的变化大,需要动态分配压缩率的方法。
创新点1:根据热点token比率衡量冗余性
记注意力头个数
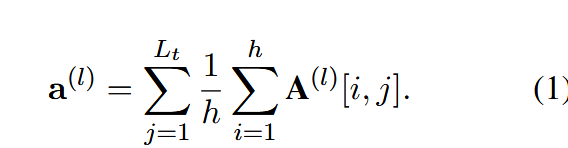
最终热点token比率可定义为:

其中
创新点2:时间自适应压缩率分配
将每
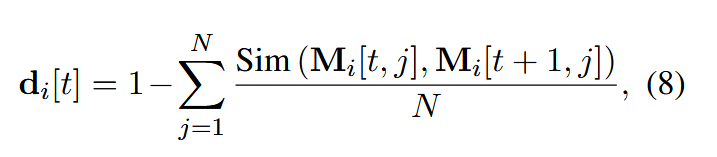
其中Sim(·)代表余弦相似度函数,对其求元素平均得到第i个块的平均帧距离
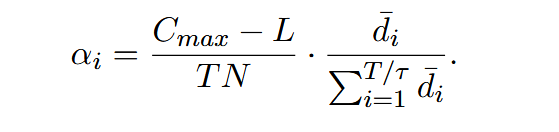
其中
创新点3:层自适应压缩率分配
对于每层先计算创新点1中每个视频token头平均提示和注意力分数,接着计算具有较大注意力得分的token数目:
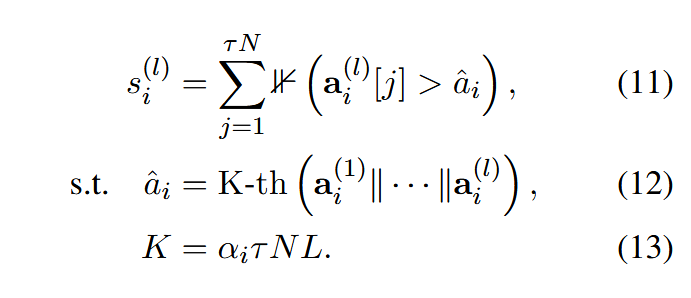
其中K-th(·)代表前K个最大的值元素,
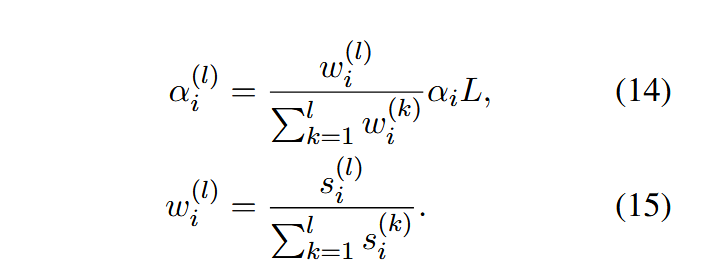
为了保证数值稳定性(部分层
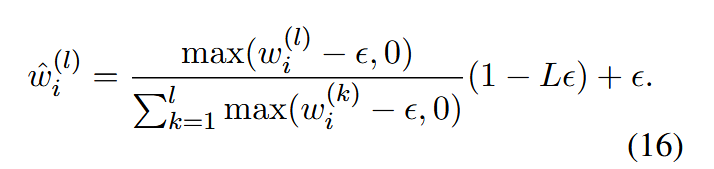
最终根据该压缩率进行KV Cache里的token压缩: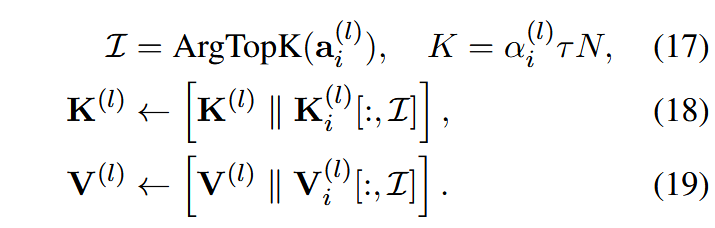
本博客所有文章除特别声明外,均采用 CC BY-NC-SA 4.0 许可协议。转载请注明来源 由本自性清净故,令诸爱染悉无垢!
