FlexRound
FlexRound: Learnable Rounding based on Element-wise Division for Post-Training Quantization阅读笔记
核心创新点:基于逐元素触发的灵活舍入
提出一种新的权重舍入机制
由于层不同通道输出差异大,在实际应用时,对线性层还需引入
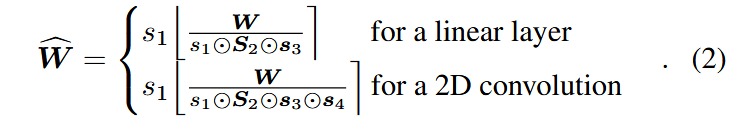
其它
暂时还没想明白每个权重都配了一个scale辅助量化,量化后使用的内存不是更大了吗,有机会再研究一下。
本博客所有文章除特别声明外,均采用 CC BY-NC-SA 4.0 许可协议。转载请注明来源 由本自性清净故,令诸爱染悉无垢!
