LRQ
LRQ: Optimizing Post-Training Quantization for Large Language Models by Learning Low-Rank Weight-Scaling Matrices阅读笔记
motivation
- 仅权重量化只在小batch推理时加速才明显,权重激活量化则精度下降太多。
- 众多方法中SmoothQuant和FlexRound都使用了硬件有好的per-tensor静态量化,但前者精度下降过高,后者因为要学习过多参数泛化性能不够好(MMLU上表现不够理想)。
创新点:权重矩阵低秩分解
权重分解核心公式:
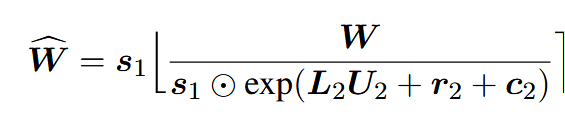
其中
最终目标为最小化块量化损失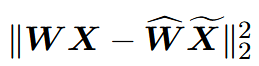
本博客所有文章除特别声明外,均采用 CC BY-NC-SA 4.0 许可协议。转载请注明来源 由本自性清净故,令诸爱染悉无垢!
