PTQ161
PTQ1.61: Push the Real Limit of Extremely Low-Bit Post-Training Quantization Methods for Large Language Models阅读笔记
总结
- 过往研究多使用无结构的细粒度掩码来判断是否为显著(salient)权重,本方法改进为一维结构掩码,同一个通道使用同一个掩码,每个权重只需额外增加0.0002位。
对于二值化的非显著权重,为了将隐含的行间相关性和角度偏差纳入考虑范围内,使用了以块为单位的优化策略。
提出量化预处理的新范式,在量化前使用restorative LoRA对预训练模型进行处理,使得显著权重能够以行为单位聚集。
创新点1:显著性权重的结构性掩码
将激活
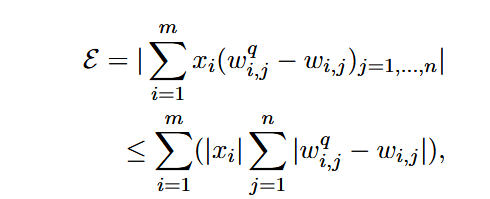
这里的
创新点2:块状优化策略
使用MSE衡量数值偏差,使用余弦相似度衡量角度偏差,最终距离指标为:
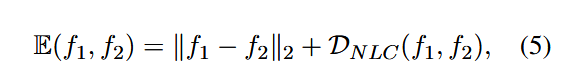
其中:
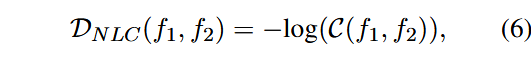
其中
最终优化目标为:
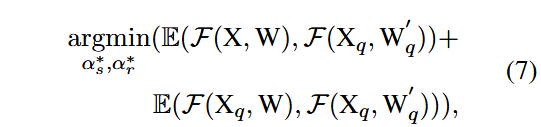
第一个分支旨在减小量化误差,第二个分支用于减小量化相同输入时的输出差异。
非显著权重反量化公式为:
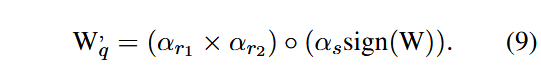
创新点3:量化预处理
LoRA论文中认为,当针对特定任务对模型进行微调时,权重补偿呈现低秩特性。这表明微调可能将重要信息补偿到权重矩阵的特定维度中,进而本文通过再预训练数据集上使用轻量级restorative LoRA对原始模型进行处理,从而使得显著权重集中到某些行,更加适宜于量化。
本博客所有文章除特别声明外,均采用 CC BY-NC-SA 4.0 许可协议。转载请注明来源 由本自性清净故,令诸爱染悉无垢!
