MQuant
MQuant: Unleashing the Inference Potential of Multimodal Large Language Models via Full Static Quantization阅读笔记
motivation
- 多模态模型有大量视觉token,使得推理速度变慢,首token延迟变长,per-token dynamic quantization加剧了这个问题。
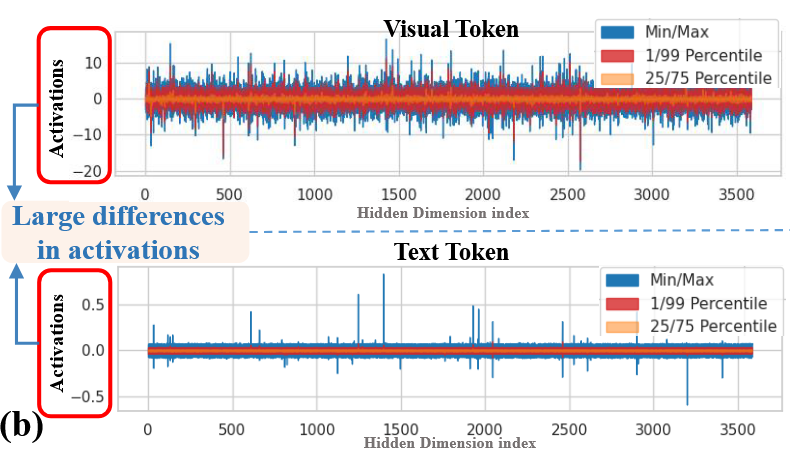
- 不同模态间激活差异大,视觉token激活范围通常比文字token大,文字token激活范围通常接近0。
- Hadamard 旋转会引入新outlier。
创新点1:特定模态的静态量化(MSQ)
对于不同模态使用不同的静态per-tensor scale,量化公式:
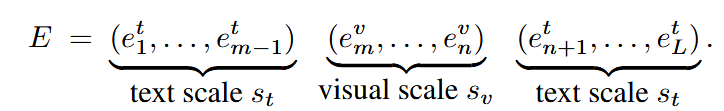
创新点2:等价注意力变换(AIFS)
为了避免重复对交错模态的输入进行处理,减少内存消耗,将所以视觉token移至最前将掩码由
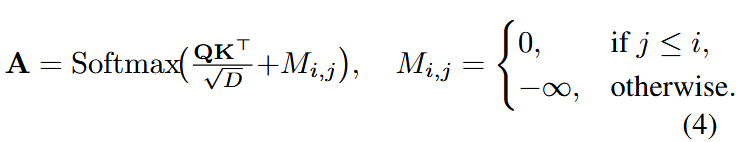
重定义为:

创新点3:旋转幅度抑制(RMS)
过往研究表明较低的不相干性
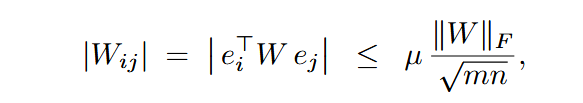
然而大部分Hadamard转换使用的矩阵第一行和第一列元素都相同,使得转换后的第一个channel为:
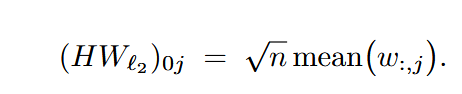
当满足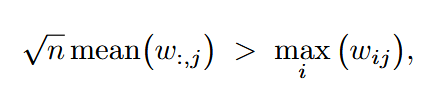 转换后第一列就会出现outlier。
转换后第一列就会出现outlier。
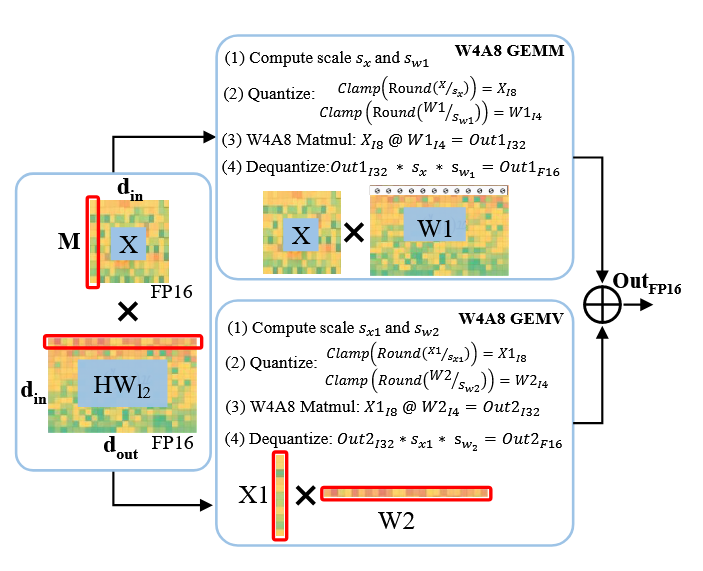
因此,将转换后会出现outlier的权重行单独拆分出来进行计算,为了避免重复计算在转换分支中置0,最后再相加。
本博客所有文章除特别声明外,均采用 CC BY-NC-SA 4.0 许可协议。转载请注明来源 由本自性清净故,令诸爱染悉无垢!
