CASP
CASP: Compression of Large Multimodal Models Based on Attention Sparsity阅读笔记
总结
- 认为多模态模型的输入天然带有的冗余属性导致了其及其稀疏的attention map(与其backbone的LLM比较)。
- 证明了attention map的稀疏性决定了
、 量化误差的上界,越稀疏上界则越小。 - 低比特压缩但无需finetune,可适用于LMM和LLM。
创新点1:基于数据感知与稀疏性的
- 计算校准数据的协方差矩阵 C,然后通过 Cholesky 分解获得下三角矩阵 L。接着,将白化矩阵 A 定义为 L 的逆矩阵。通过将 A 应用到校准数据上,将数据白化,再利用白化数据计算 attention map。
低秩分解后的 attention map:
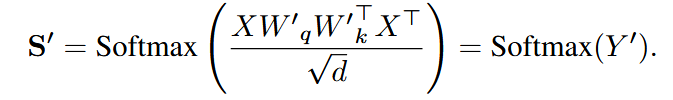
定义稀疏性为 attention map 中值高于阈值
的比例,则优化目标为:
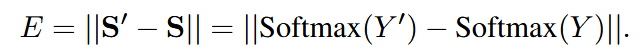
创新点2:最优量化比特分配
- 定义了块重要性分数:
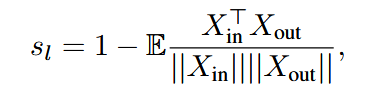
- 减轻过度稀疏带来的不利影响,采用熵正则化
来实现平滑。其中 是第 层分配到的 数。最终优化目标为:
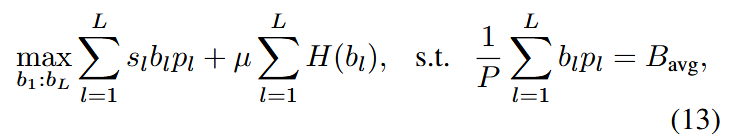
- 最优分配解:
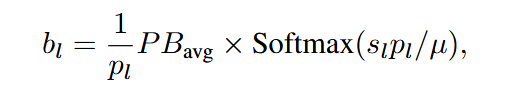
本博客所有文章除特别声明外,均采用 CC BY-NC-SA 4.0 许可协议。转载请注明来源 由本自性清净故,令诸爱染悉无垢!
