OSTQuant
OSTQuant: Refining Large Language Model Quantization with Orthogonal and Scaling Transformations for Better Distribution Fitting阅读笔记
motivation
- 现有LLM量化面临两大挑战:
- LLM的权重与激活值通常具有非对称、重尾分布特征以及通道间方差差异。
- 校准集较小,传统损失函数(如交叉熵)容易在小样本下过拟合
- 现有改善数据分布的方法依赖启发性设计,缺乏系统性评估。
创新点1:量化空间利用率(QSUR)
对于原始数据占据的超体积,可以看作一个由协方差矩阵决定的椭圆形。对于一个d维的数据
,其超体积计算公式为 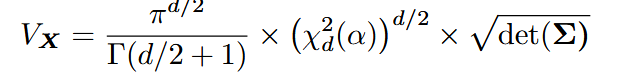
其中
是椭球体半轴长度的连乘,卡方分布的引入,使其在给定置信水平 α 下能够包含相应比例的数据点。 量化空间的体积由数据沿着主轴的极值点决定,公式:
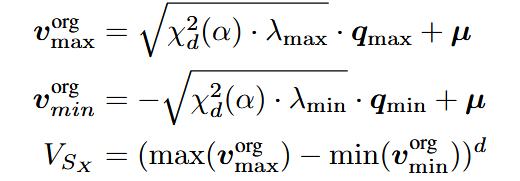
其中
为对应于相应特征值的特征向量,个人猜测最小特征值前面应该有个负号(?)。 则QSUR可定义为原始数据体积与量化空间体积的比值:
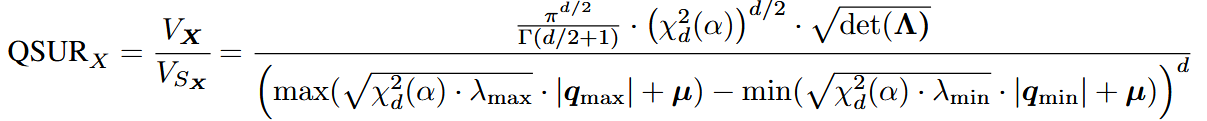
PS:个人理解这是似乎应该是加号(?),然后忽略平均向量,假设最大最小特征值绝对相等,可简化为
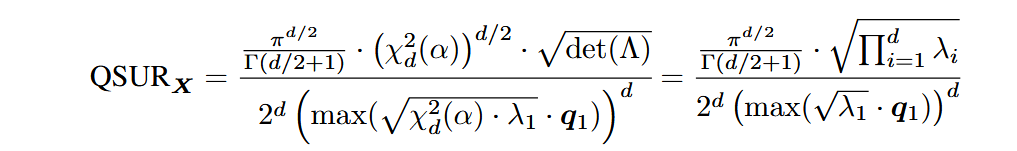
应用:
- 在激活X上施加变换T可表示为
,其中Q是特征向量的单位正交矩阵,当 是,QSUR达到最大,c可以为任意常量。
- 在激活X上施加变换T可表示为
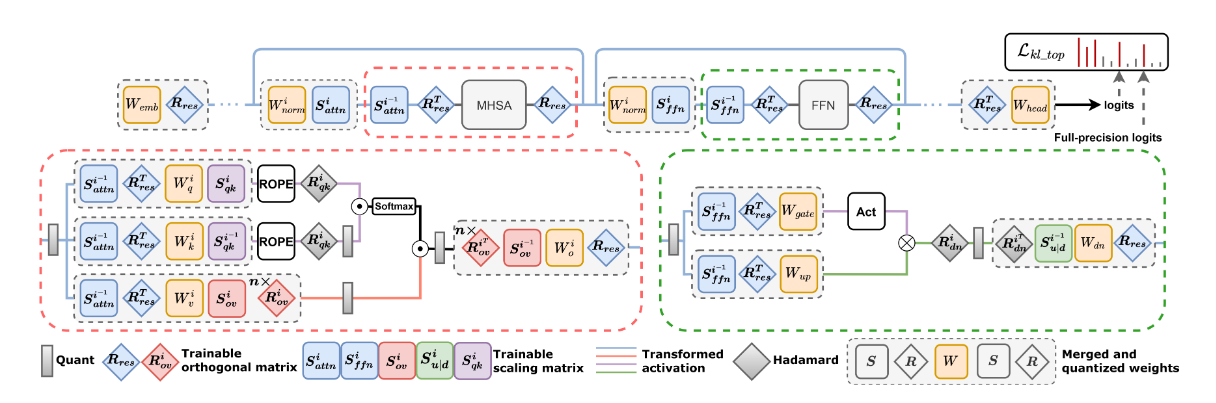
创新点2:缩放旋转对
- 定义变换对
,其中 为对角矩阵负责缩放;O为正交矩阵负责旋转,O使用一阶梯度进行优化。 - 使用权重异常值最小化初始化(WOMI)
- 使用
初始化O,d是维度数,H是全由 组成的正交矩阵。 - 对于作用于所有残差路径的全局矩阵
,将所有与残差有关的层沿着输入通道拼接再对协方差矩阵特征值分解得到特征值矩阵 ,然后用 ,其中H是标准化的Hadamard矩阵。 - 对于O-proj和V-proj层的旋转矩阵按照头的维度切分再仿照
初始化。 - 对角矩阵用单位矩阵初始化。
- 使用
创新点3:KL-TOP损失函数
- 大语言模型词汇量多,预测结果呈严重长尾分布,直接应用 KL 散度进行优化,损失可能被低概率的无信息类别主导,为训练过程引入噪声。
- KL-TOP仅计算预测概率最高的前k个类别的KL散度,避免低概率噪声对梯度更新的干扰。
- 公式:
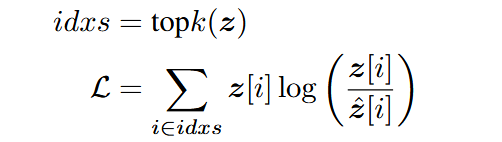
其它
WikiText2上W4A4的结果要比DuQuant好
本博客所有文章除特别声明外,均采用 CC BY-NC-SA 4.0 许可协议。转载请注明来源 由本自性清净故,令诸爱染悉无垢!
