AKVQ-VL
AKVQ-VL: Attention-Aware KV Cache Adaptive 2-Bit Quantization for Vision-Language Models阅读笔记
motivation
- 认为现有KV Cache量化没有关注到多模态token间的显著性(saliency)区别
- 观察到多模态模型在初始层优先关注文本token(文本显著性注意力,TSA),而在后续层则关注少数关键token(关键token显著性注意力,PSA)。
- 与LLM都具有’local’ attention pattern,即都会更关注临近的token
- 与LLM不同,多模态模型PSA时的pivot token不光是开头的sink token,还有其他位置的token。
创新点1:显著性token识别
TSA层的显著token:text token和recent token。
PSA层的显著token:sink token(开头)和具有大激活值的token。
对于pivot token(PSA层显著token,recent token)使用fp16保存,对于text token使用4bit量化,其余量化至2bit,使用per token dynamic asymmetric quantization with clipping。
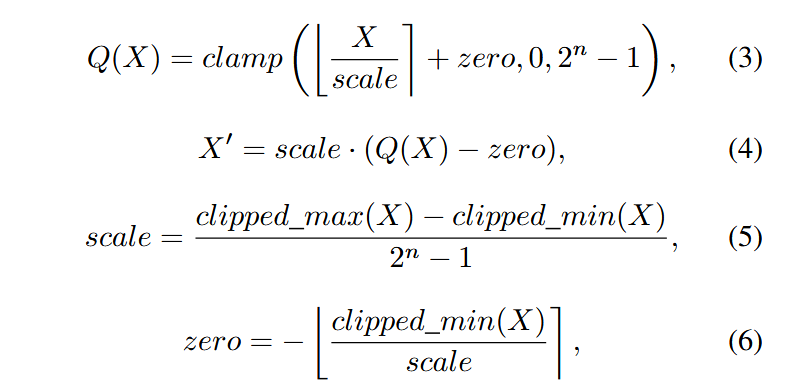
创新点2:Walsh-Hadamard矩阵抹平outliers
- 受Quarot、Spinquant启发,可使用Fast WalshHadamard Transform (FWHT)加速计算,Value的等价变化可通过讲WH矩阵融入权重矩阵离线计算。
- 矩阵构造:
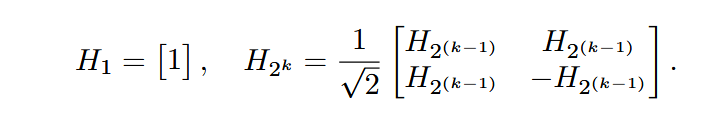
- Key等价变换:

- Value等价变换:
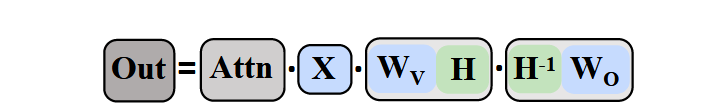
成就
第一个针对VLM的KV Cache量化工作,2bit几乎无损
reduce peak memory usage by 2.13×, support up to 3.25× larger batch sizes and 2.46× throughput.
本博客所有文章除特别声明外,均采用 CC BY-NC-SA 4.0 许可协议。转载请注明来源 由本自性清净故,令诸爱染悉无垢!
